Abstract
Query-based sound separation (QSS) effectively isolate sound signals that match the content of a given query, enhancing the understanding of audio data. However, most existing QSS methods rely on a single modality for separation, lacking the ability to fully leverage homologous but heterogeneous information across multiple modalities for the same sound signal. To address this limitation, we introduce Omni-modal Sound Separation (OmniSep), a novel framework capable of isolating clean soundtracks based on omni-modal queries, encompassing both single-modal and multi-modal composed queries. Specifically, we introduce the Query-Mixup strategy, which blends query features from different modalities during training. This enables OmniSep to optimize multiple modalities concurrently, effectively bringing all modalities under a unified framework for sound separation. We further enhance this flexibility by allowing queries to influence sound separation positively or negatively, facilitating the retention or removal of specific sounds as desired. Finally, OmniSep employs a retrieval-augmented approach known as Query-Aug, which enables open-vocabulary sound separation. Experimental evaluations on MUSIC, VGGSOUND-CLEAN+, and MUSIC-CLEAN+ datasets demonstrate effectiveness of OmniSep, achieving state-of-the-art performance in text-, image-, and audio-queried sound separation tasks.
A.Sound Separation with Queries of Different Modalities.
A.1.Text-Query
| Query | Mixture | Interference | Target | Prediction |
|---|---|---|---|---|

|
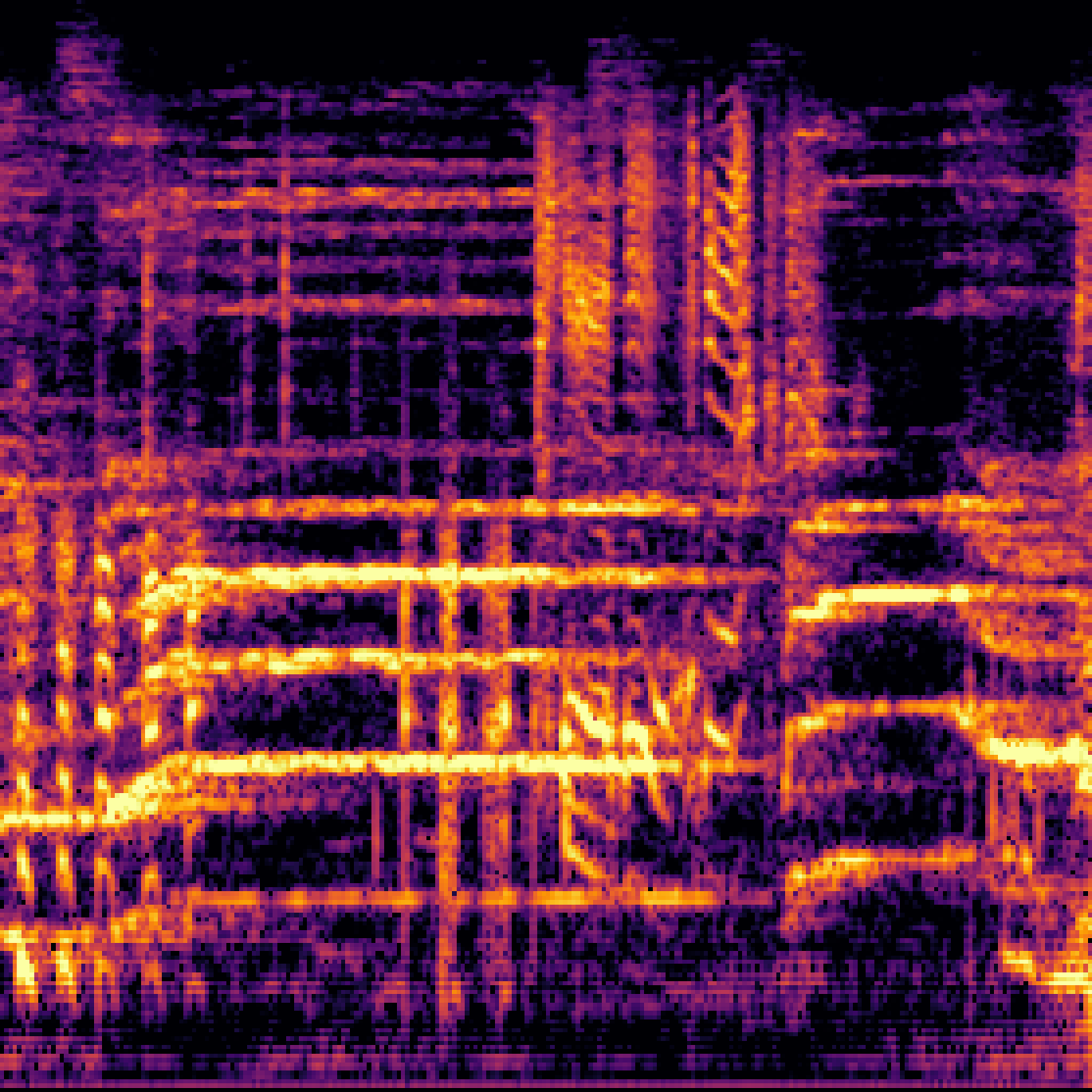
|
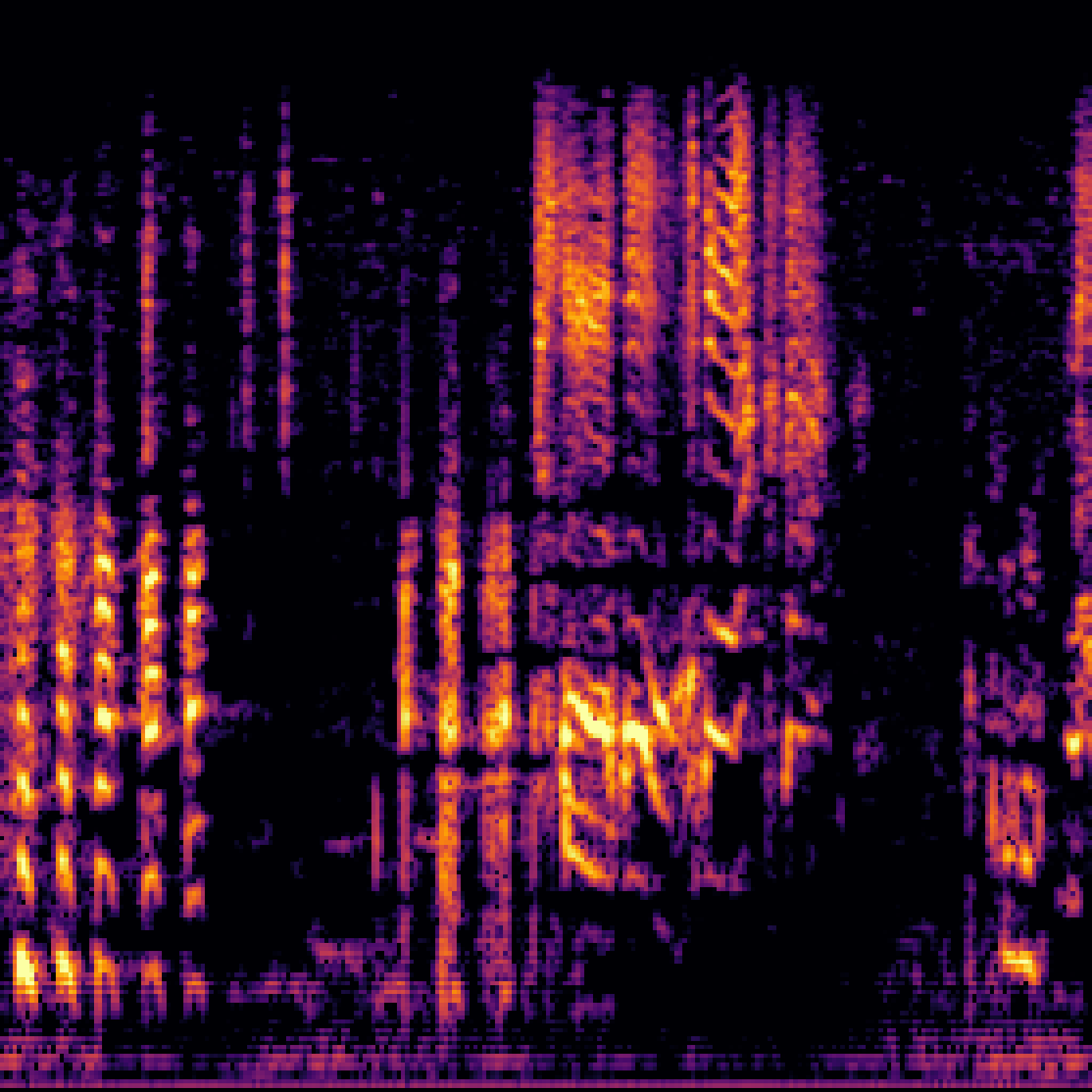
|
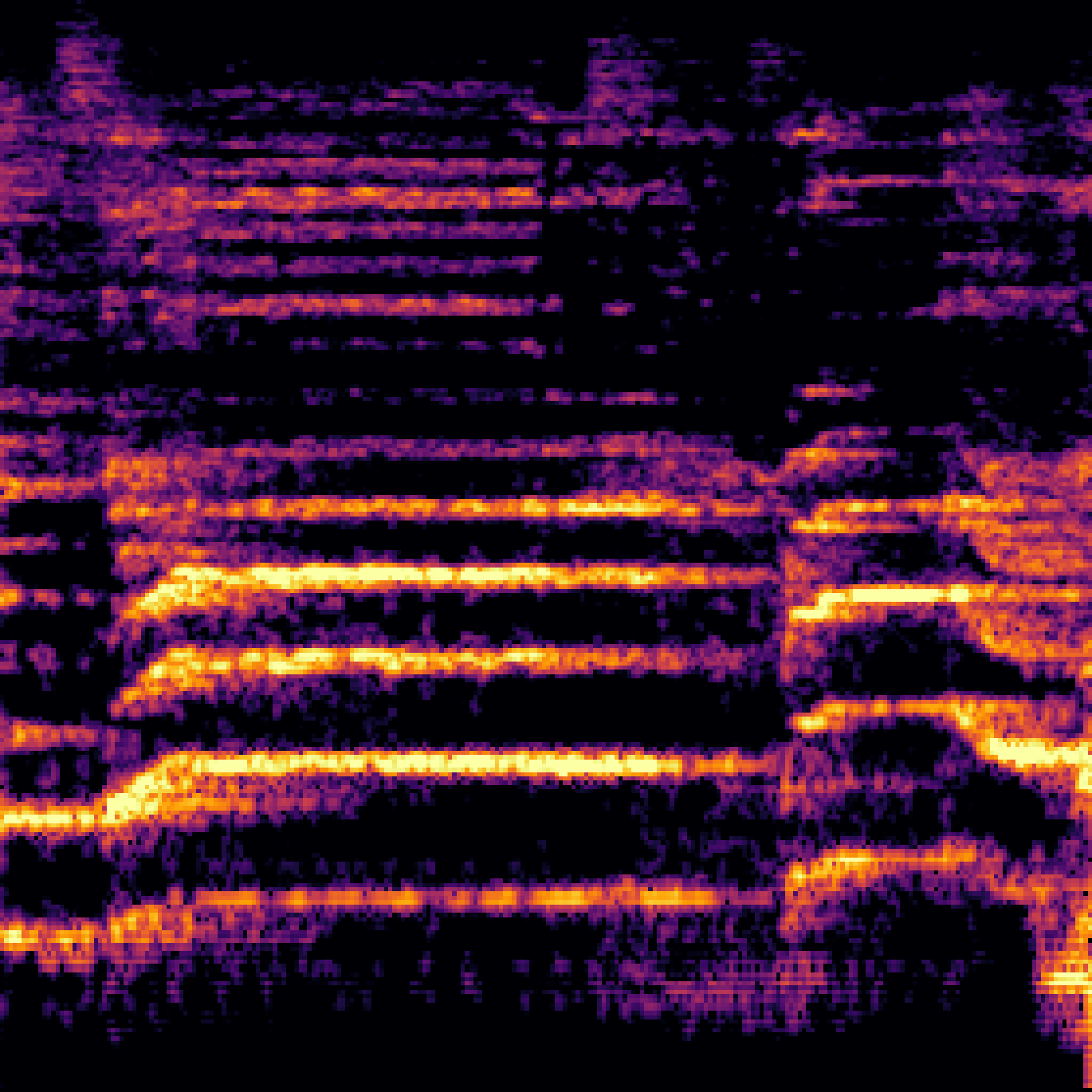
|
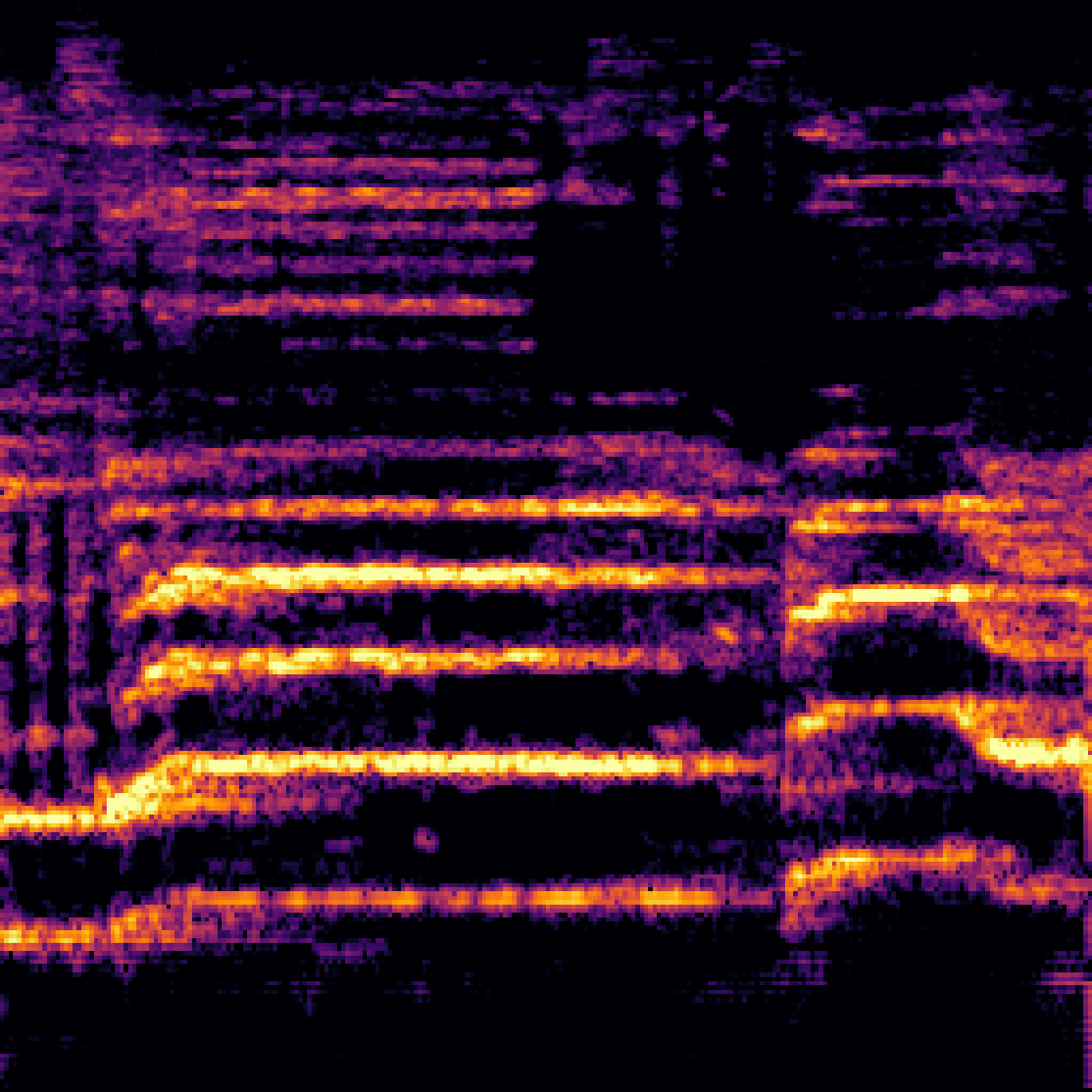
|

|
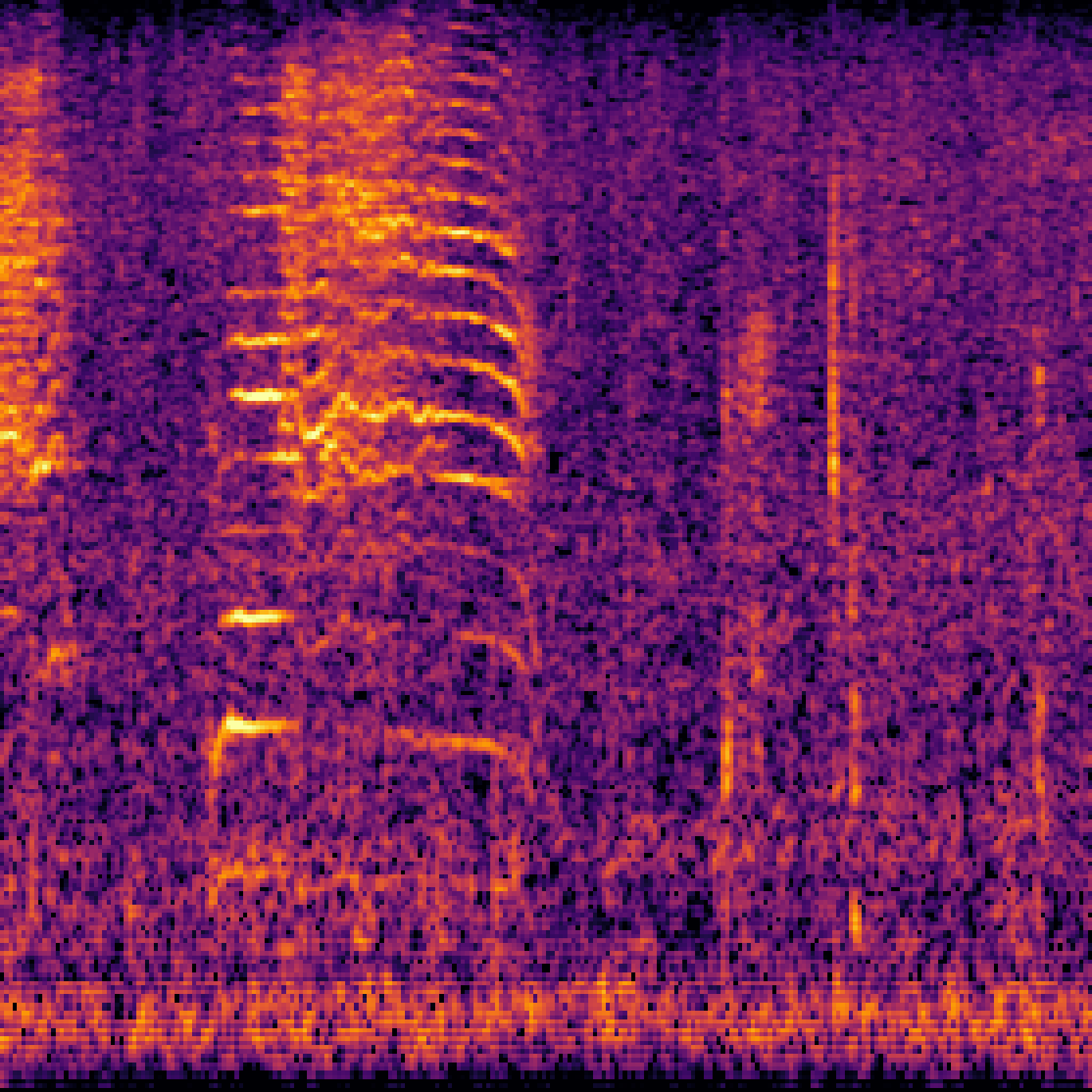
|
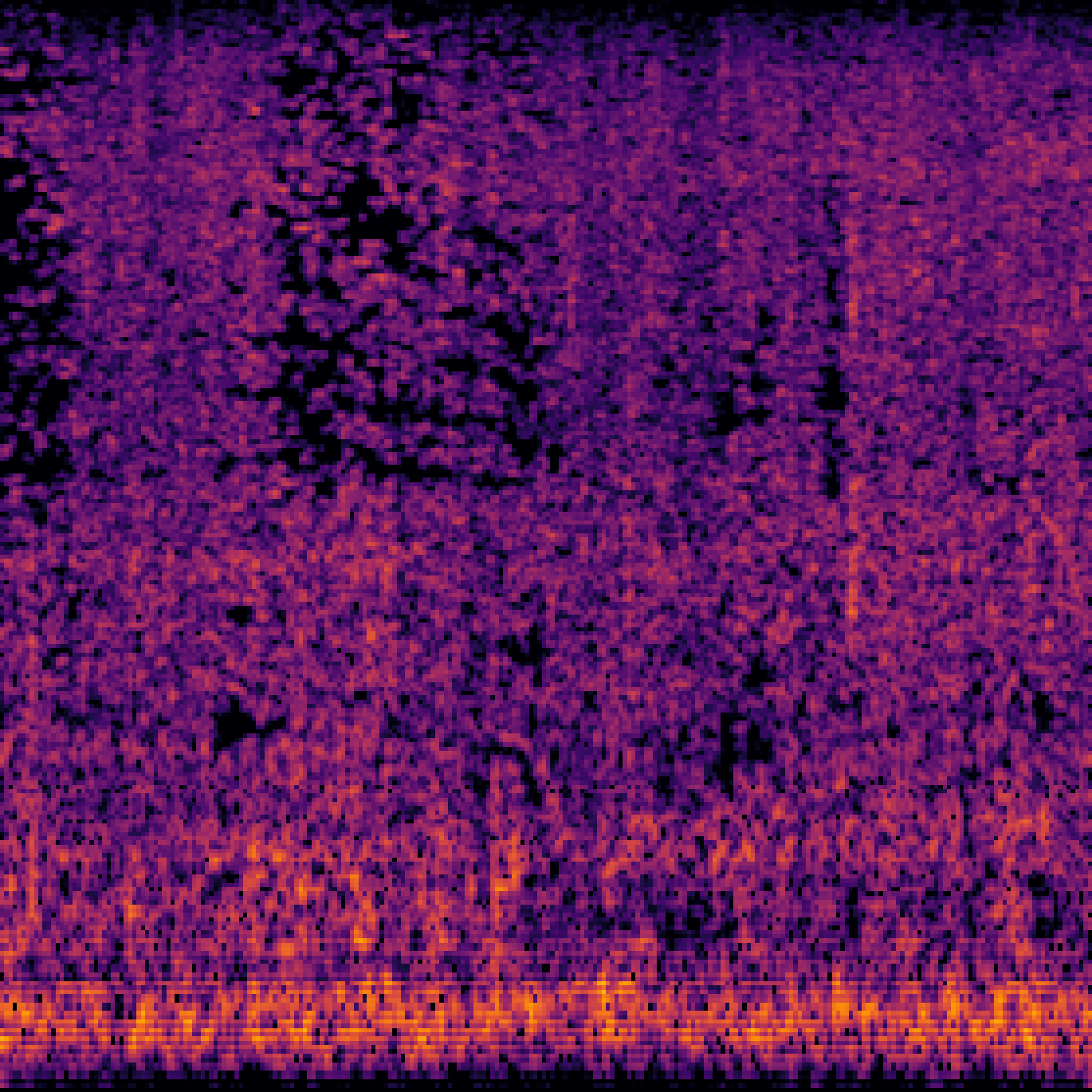
|
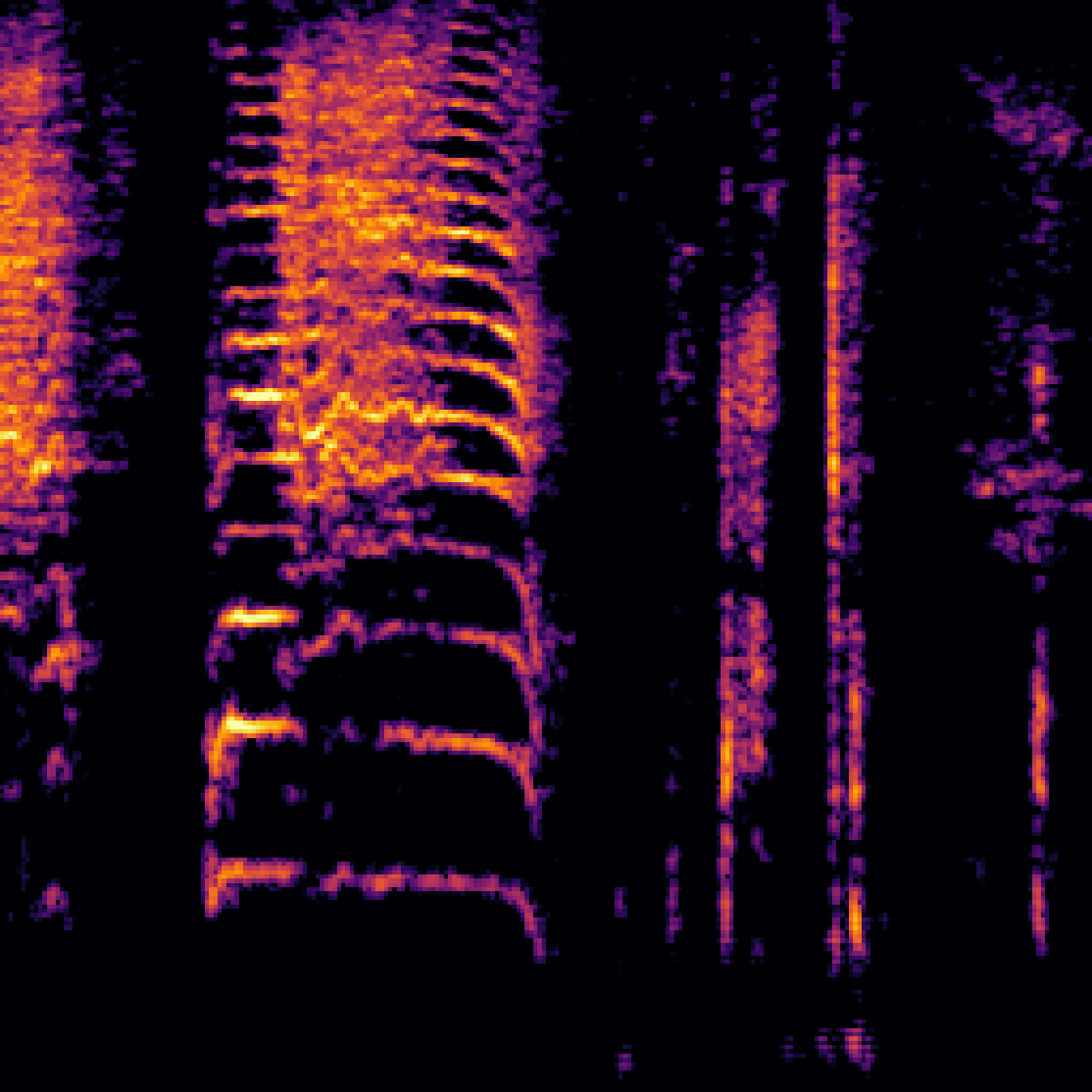
|
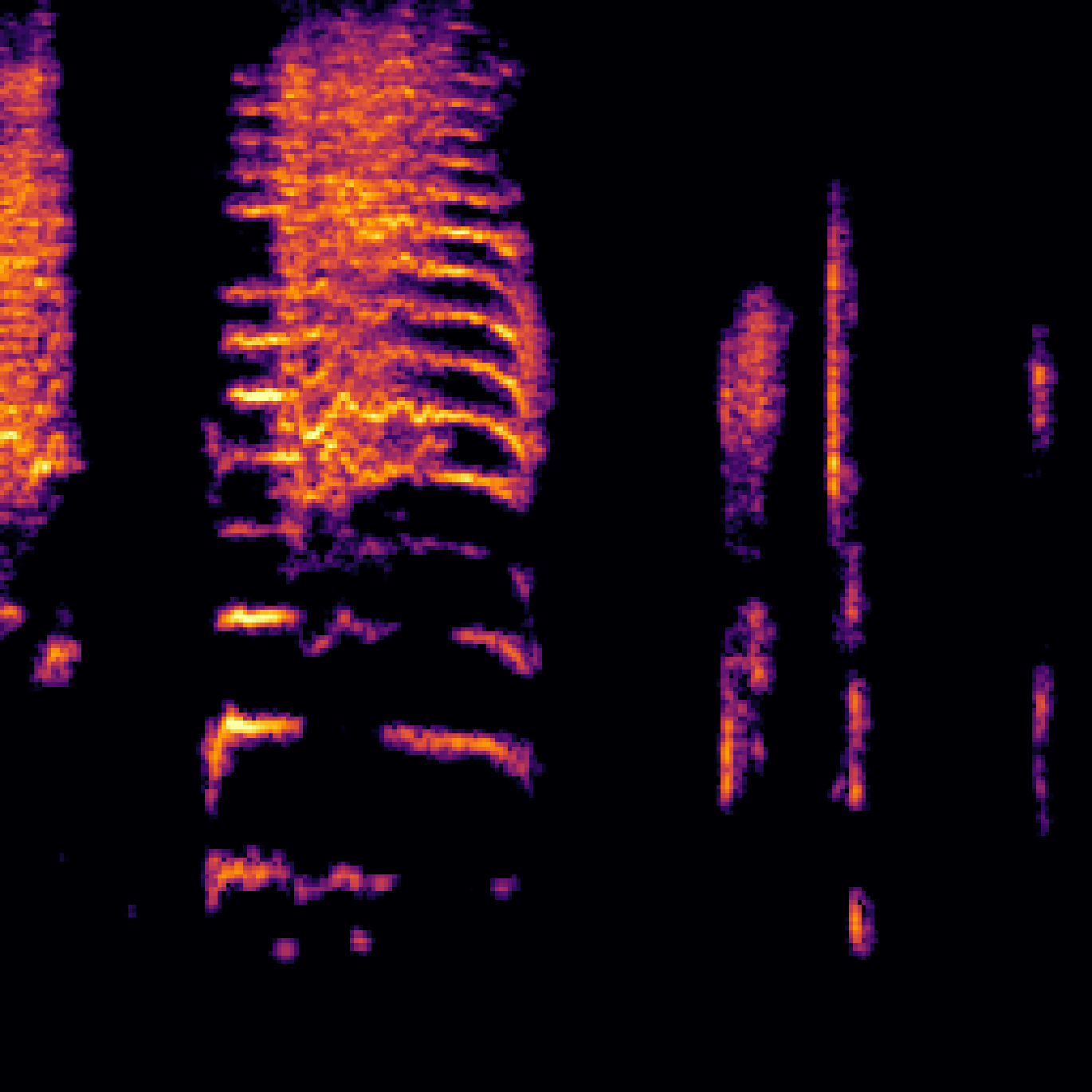
|

|
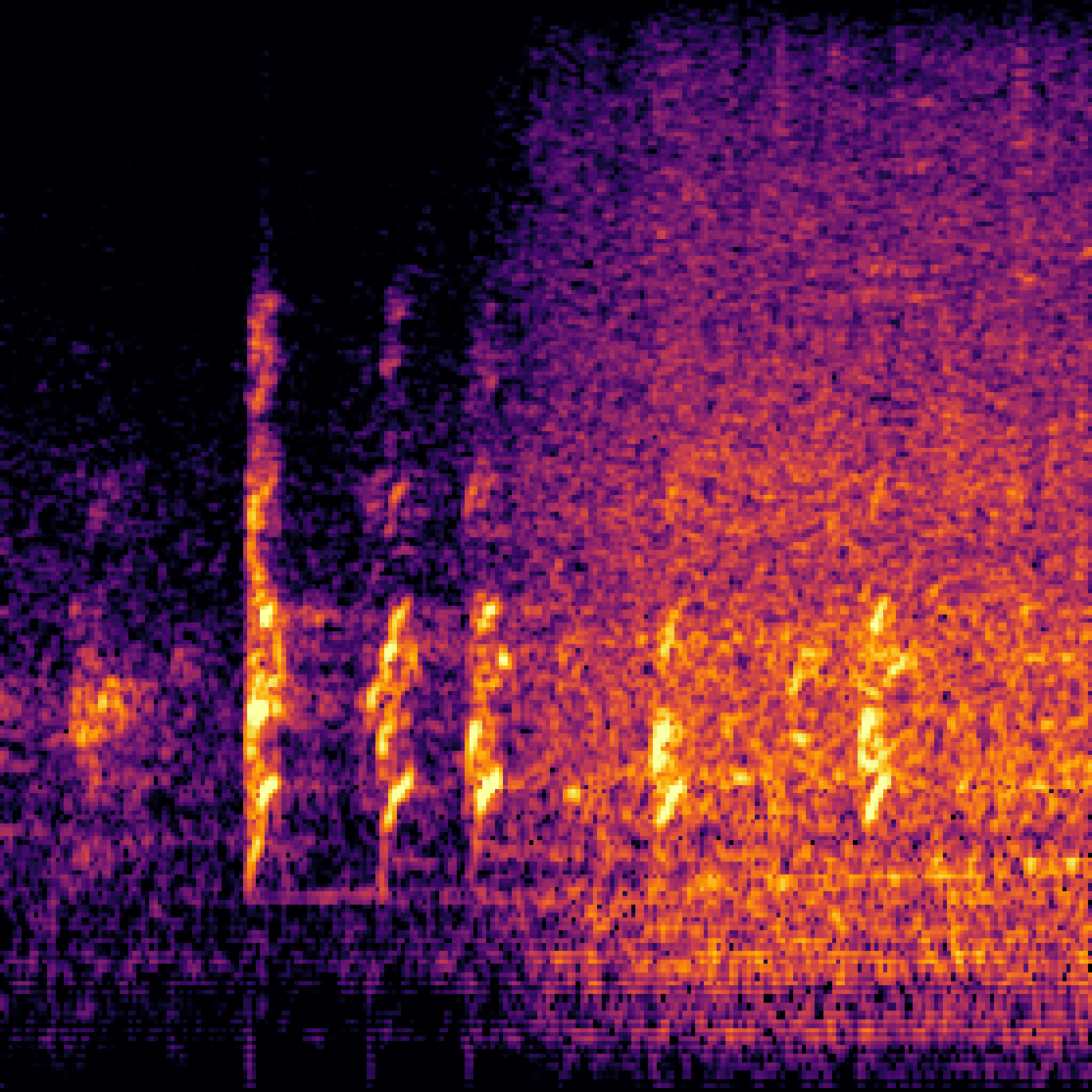
|
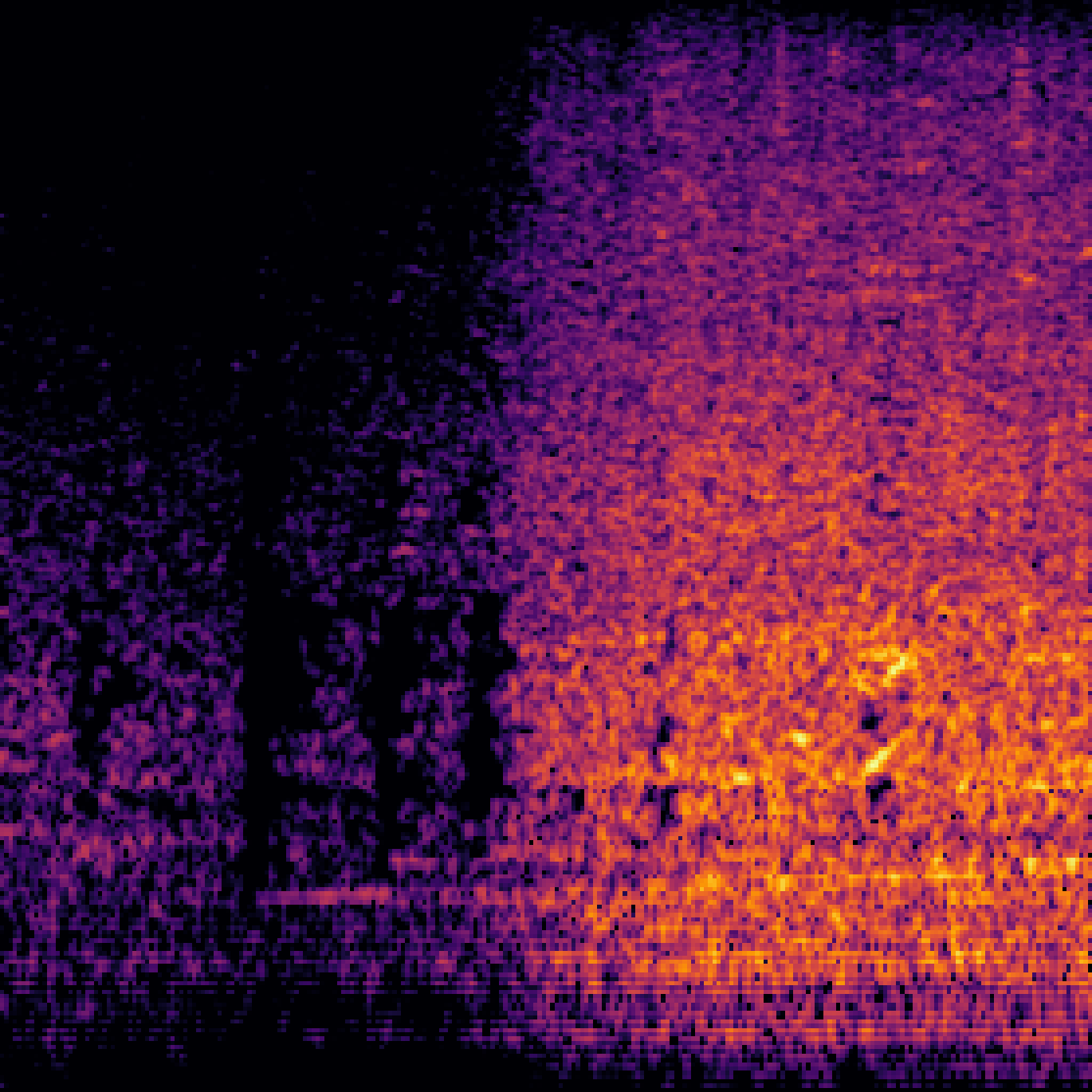
|
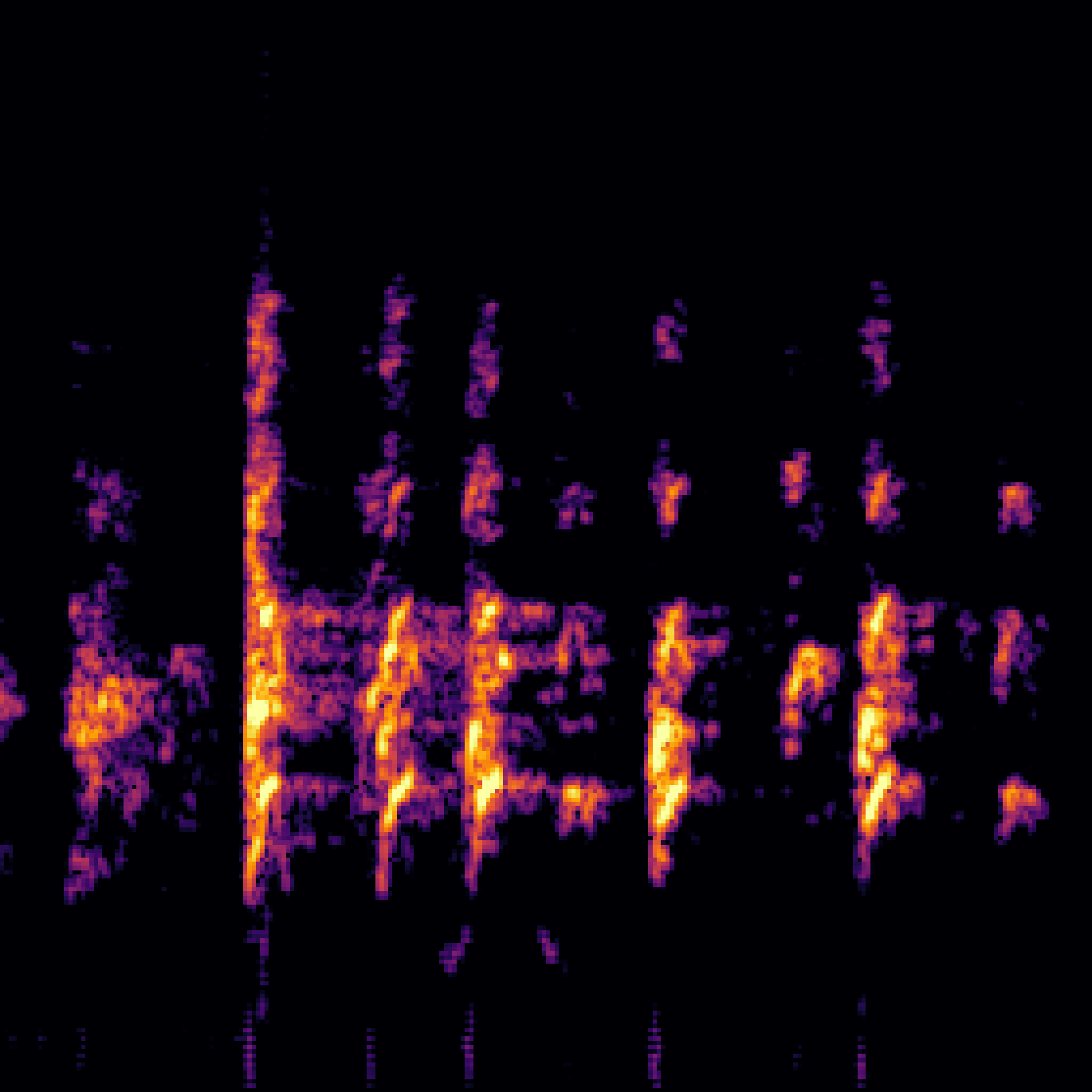
|
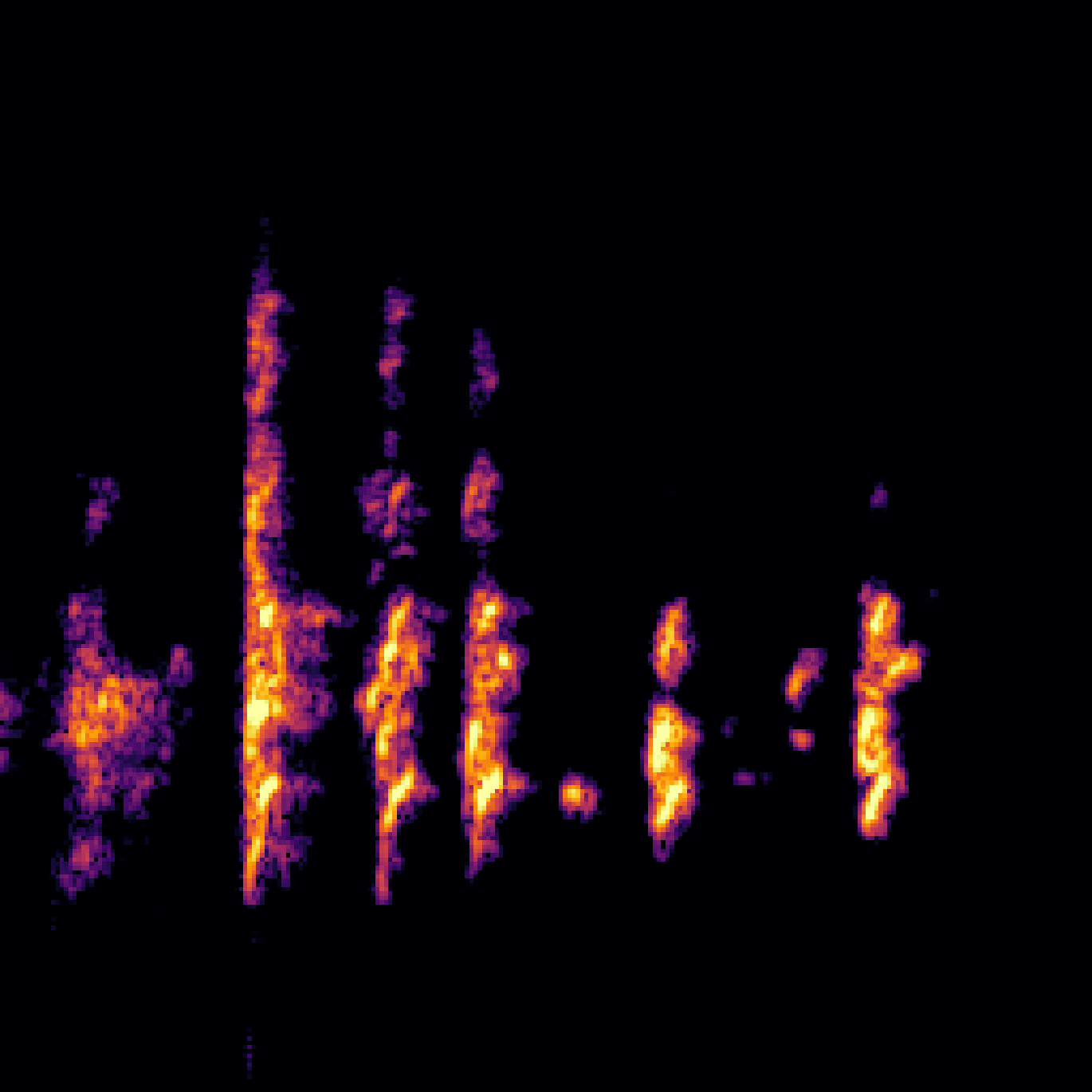
|
A.2.Image-Query
| Query | Mixture | Interference | Target | Prediction |
|---|---|---|---|---|

|
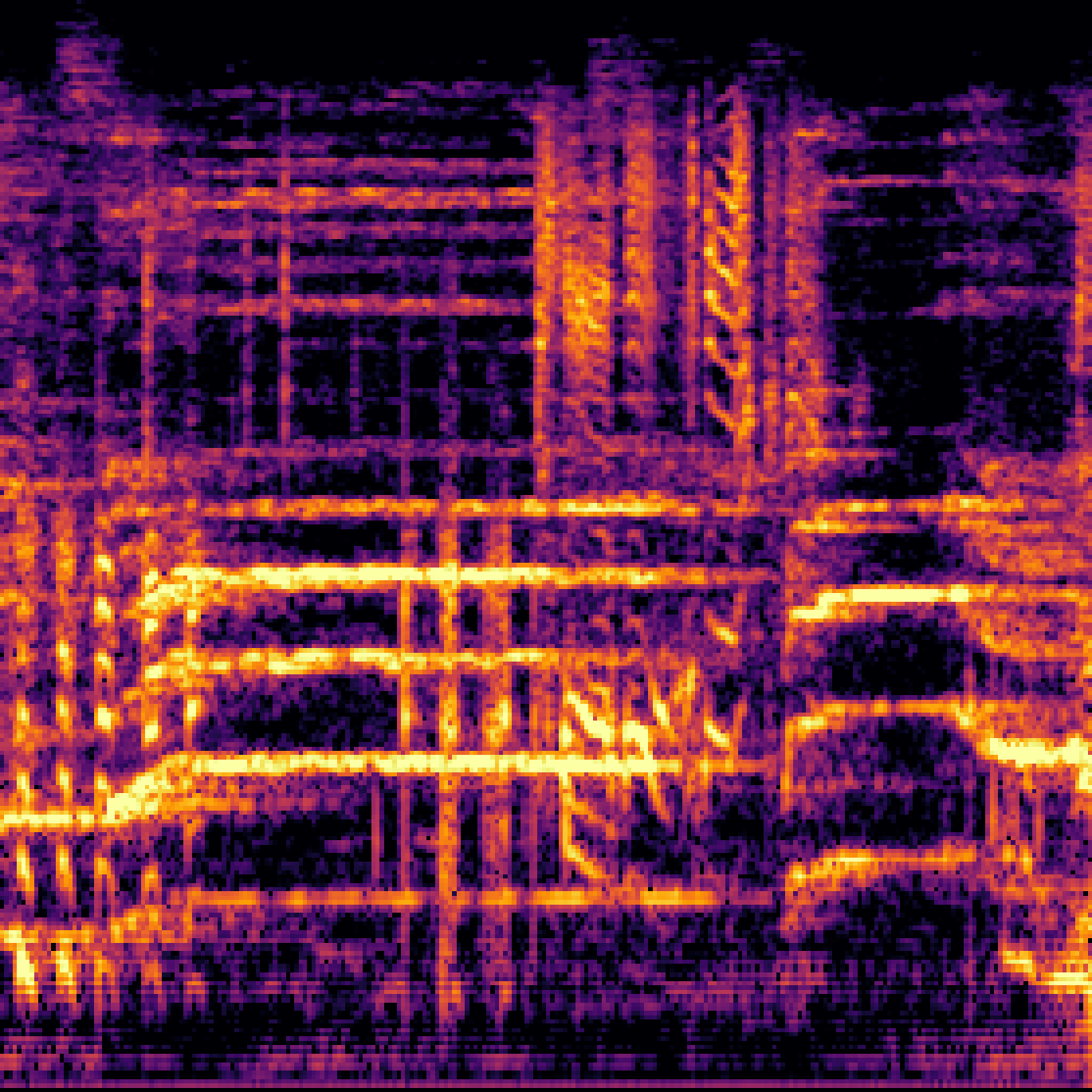
|
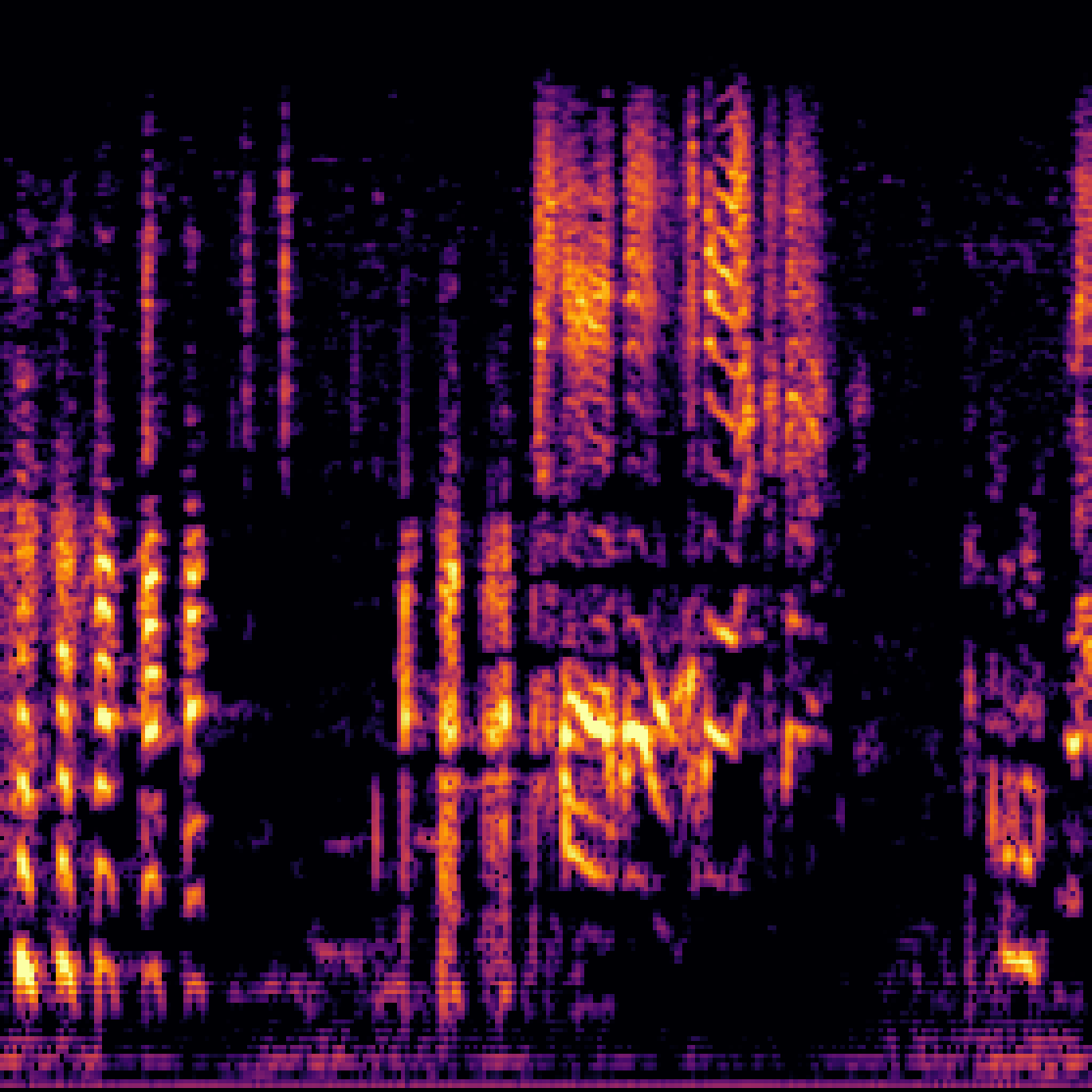
|
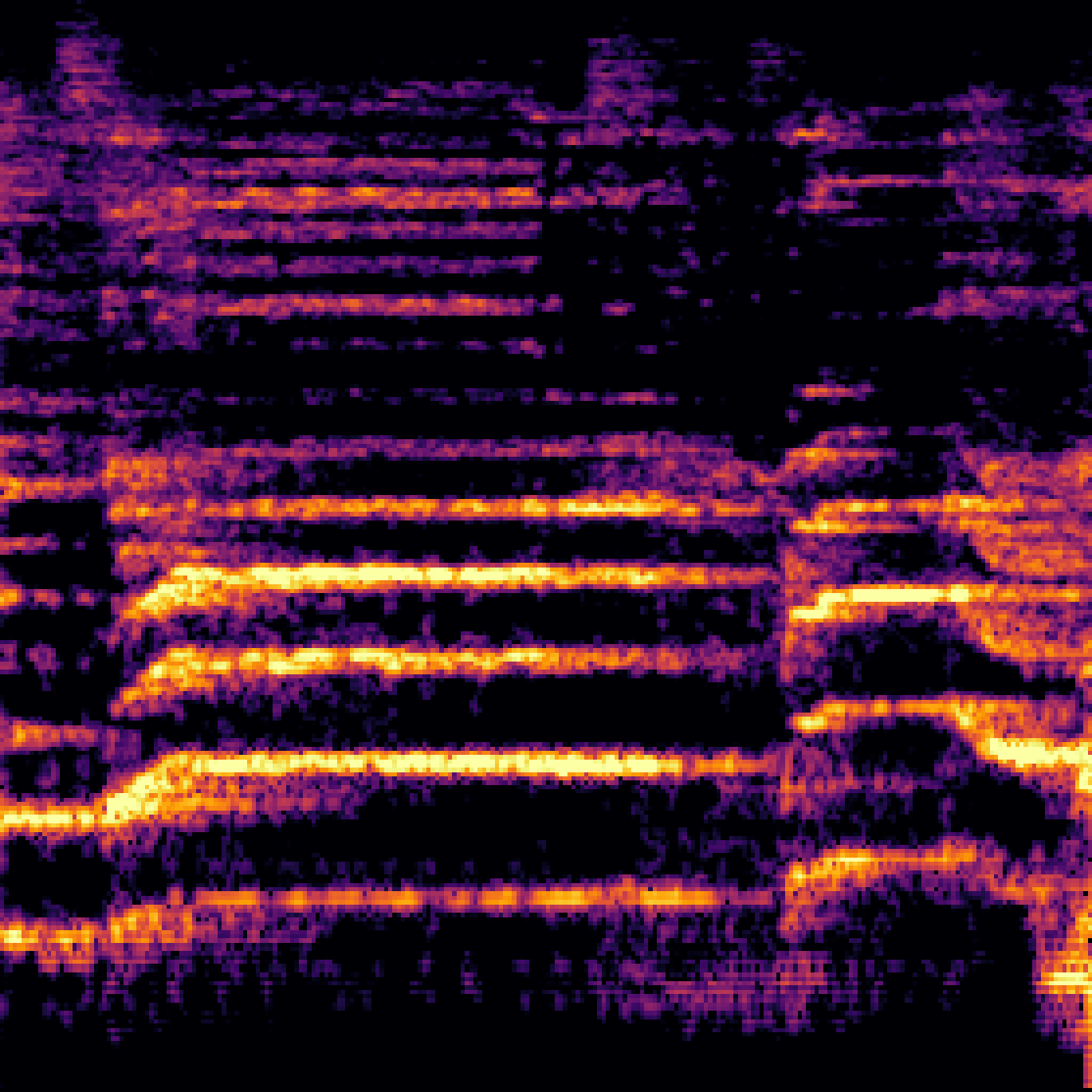
|
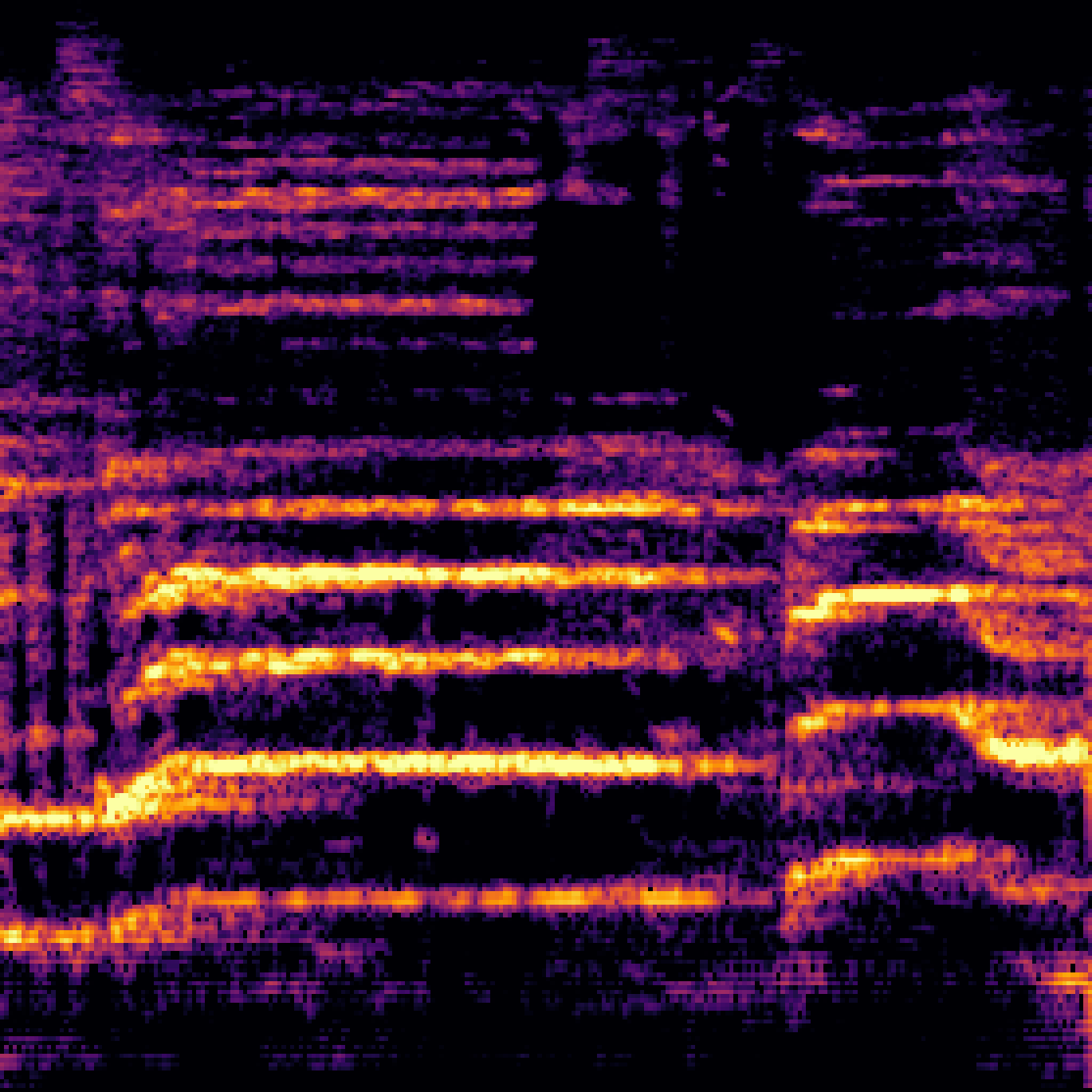
|

|
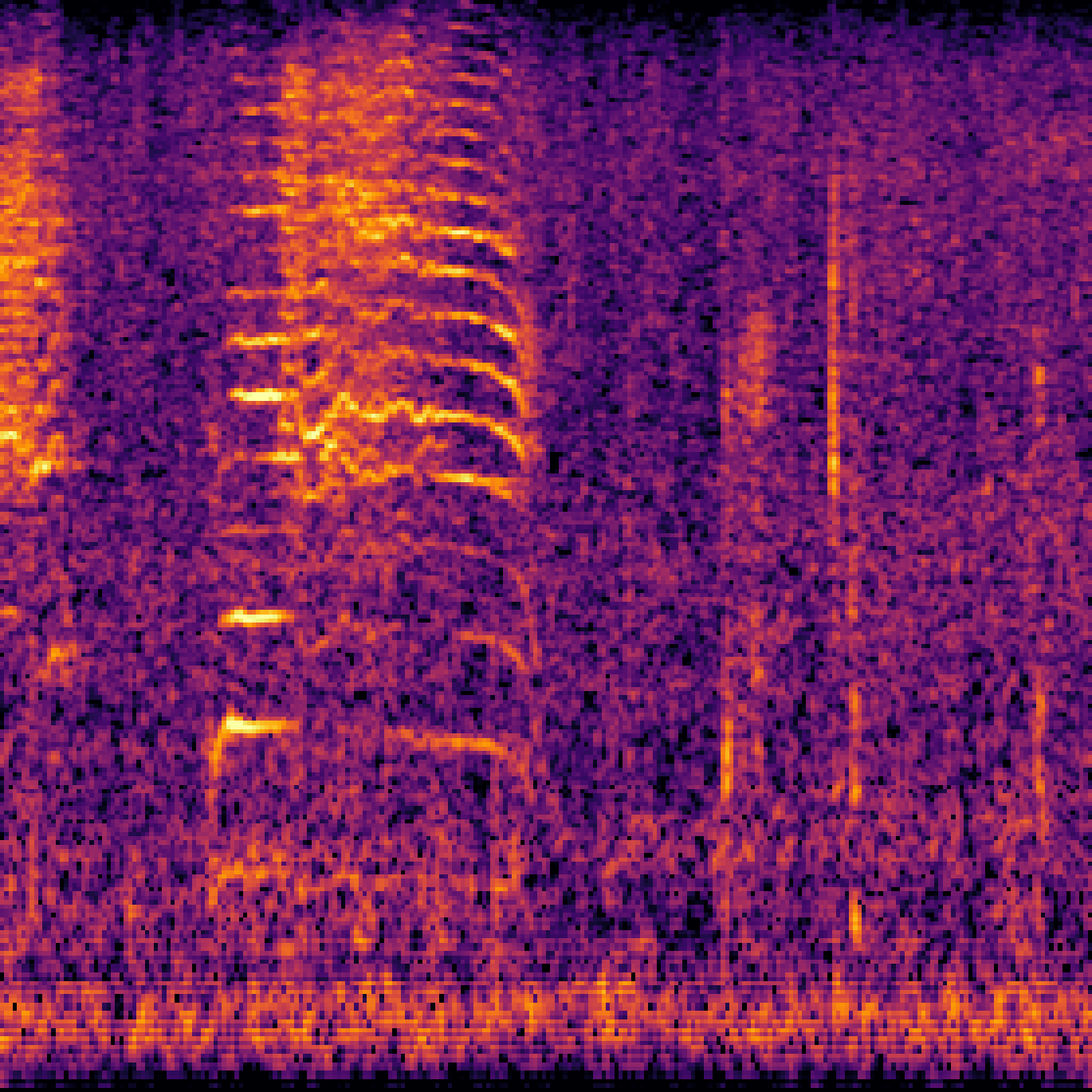
|
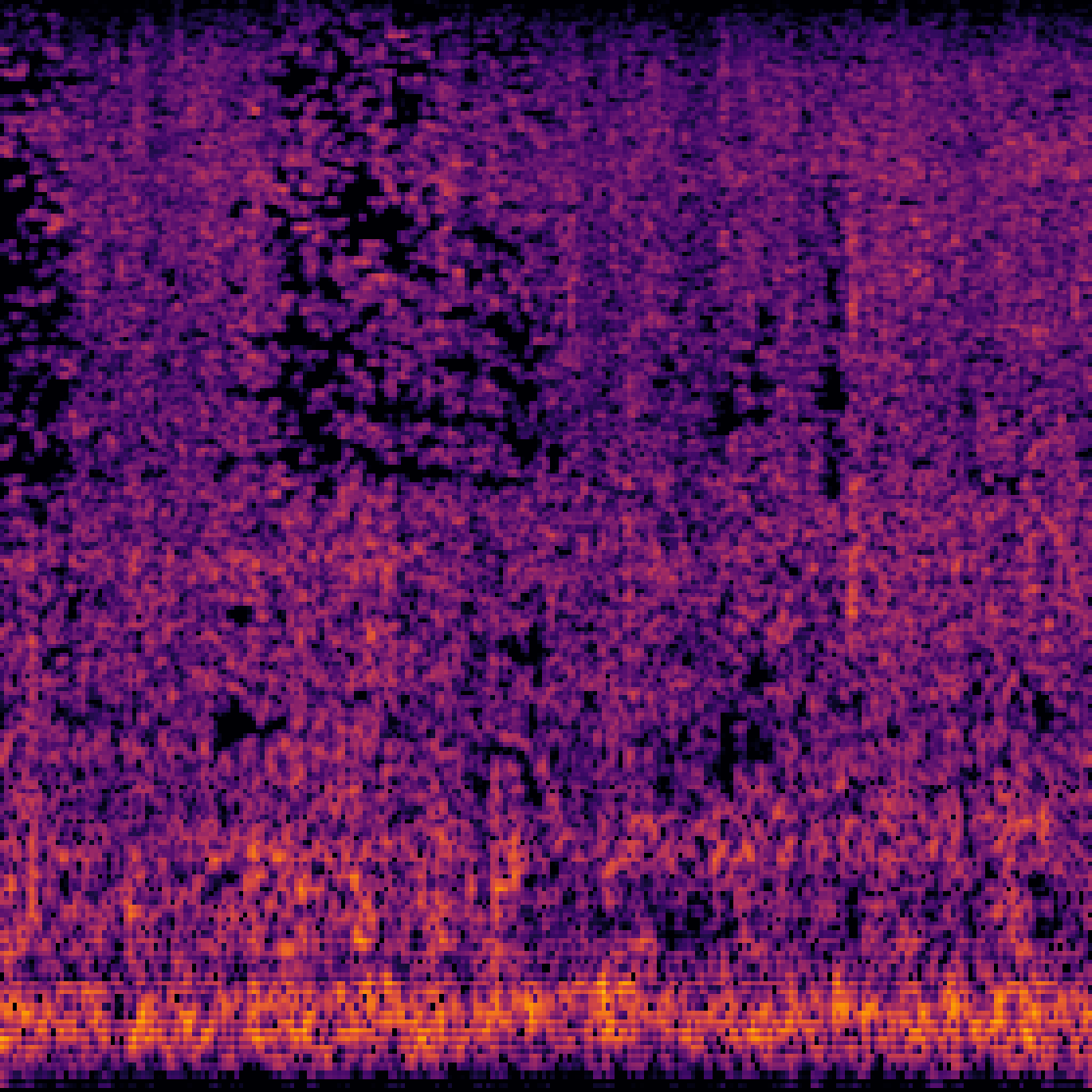
|
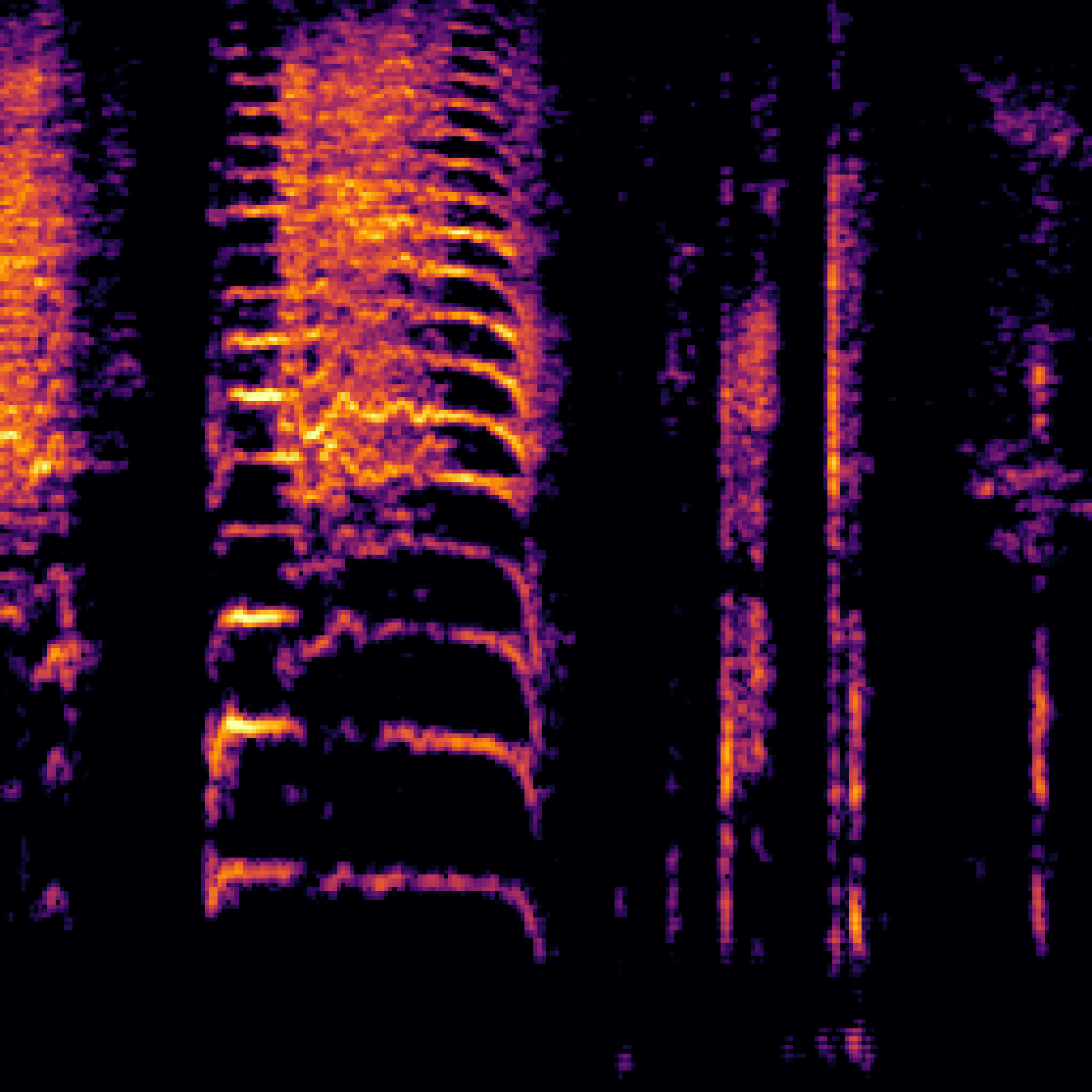
|
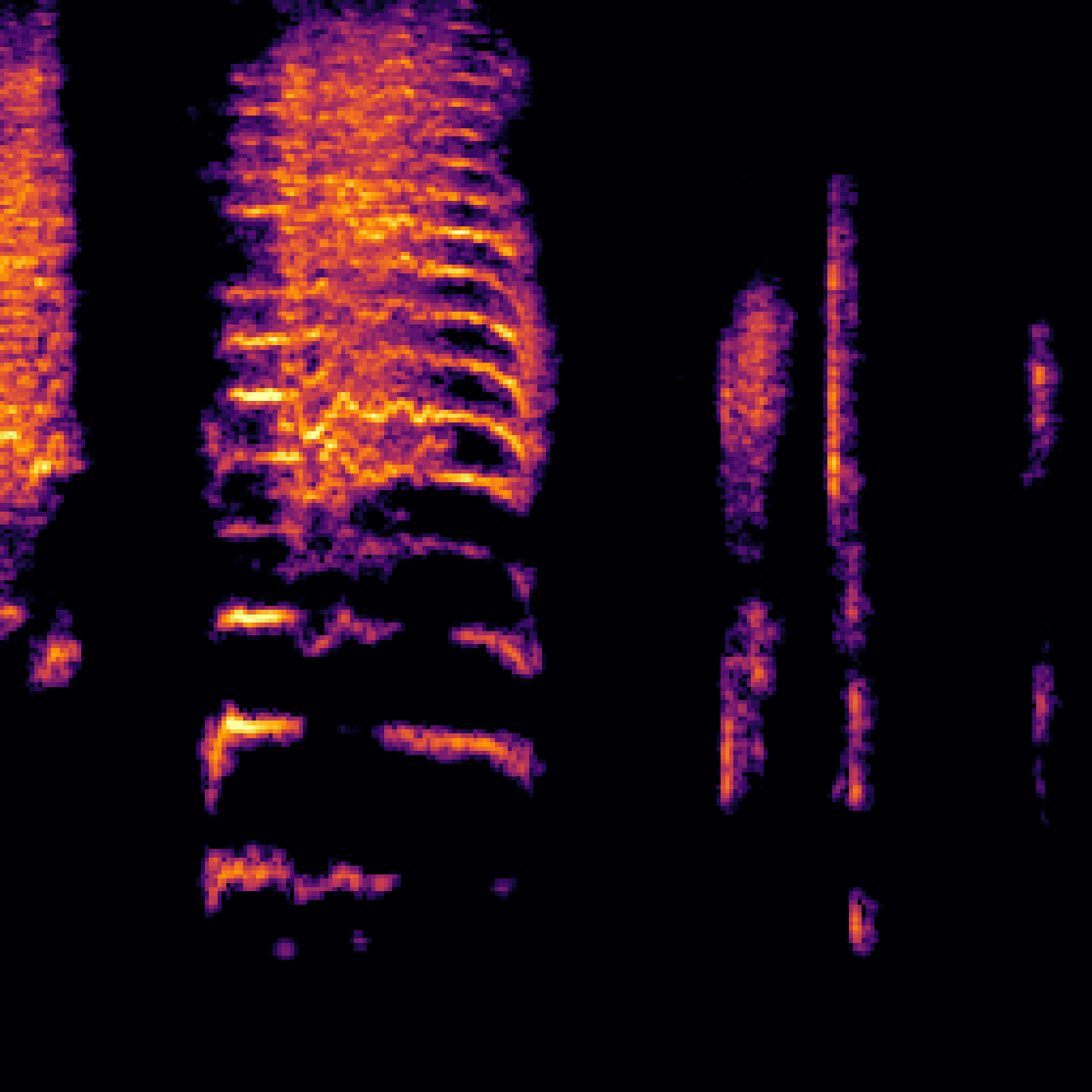
|

|
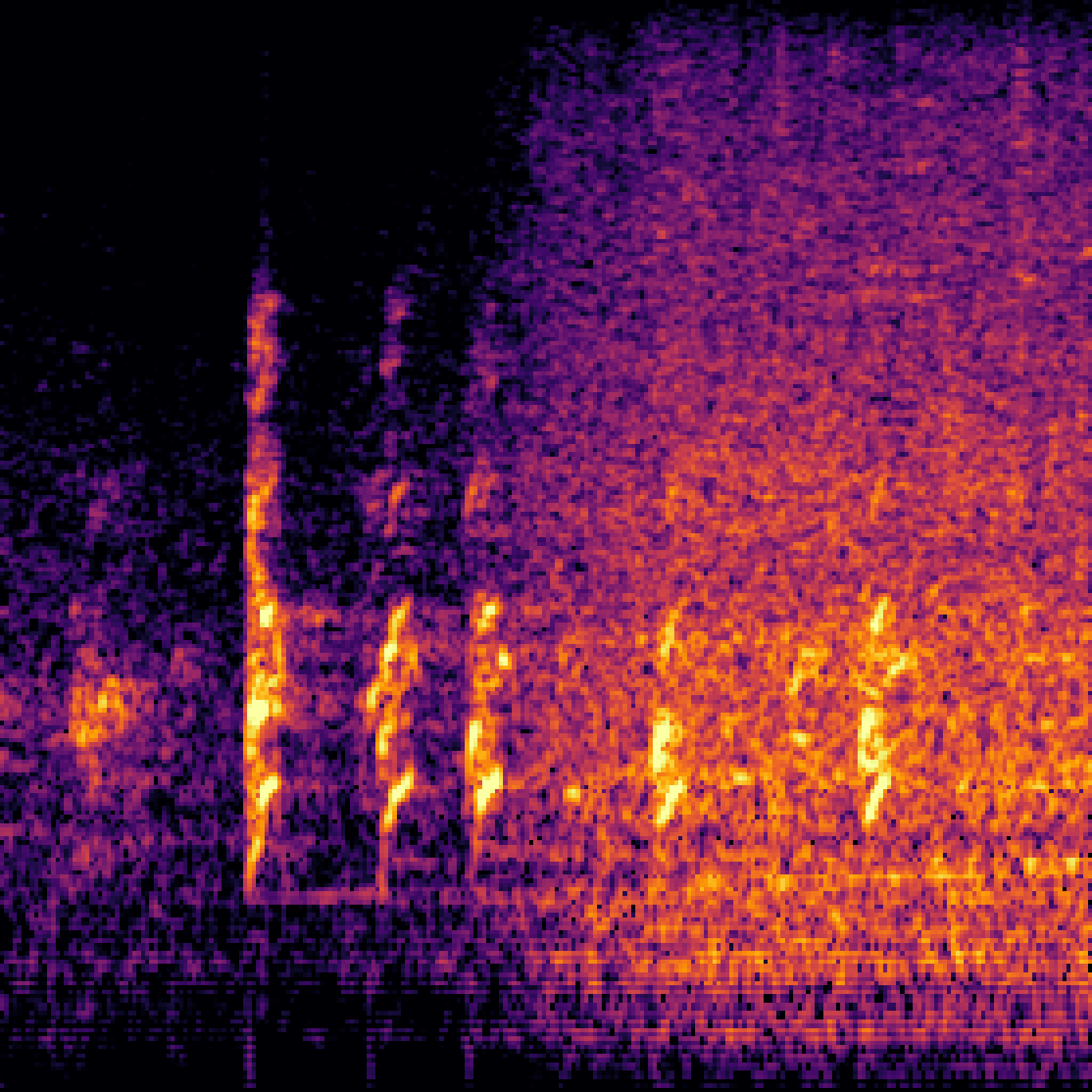
|
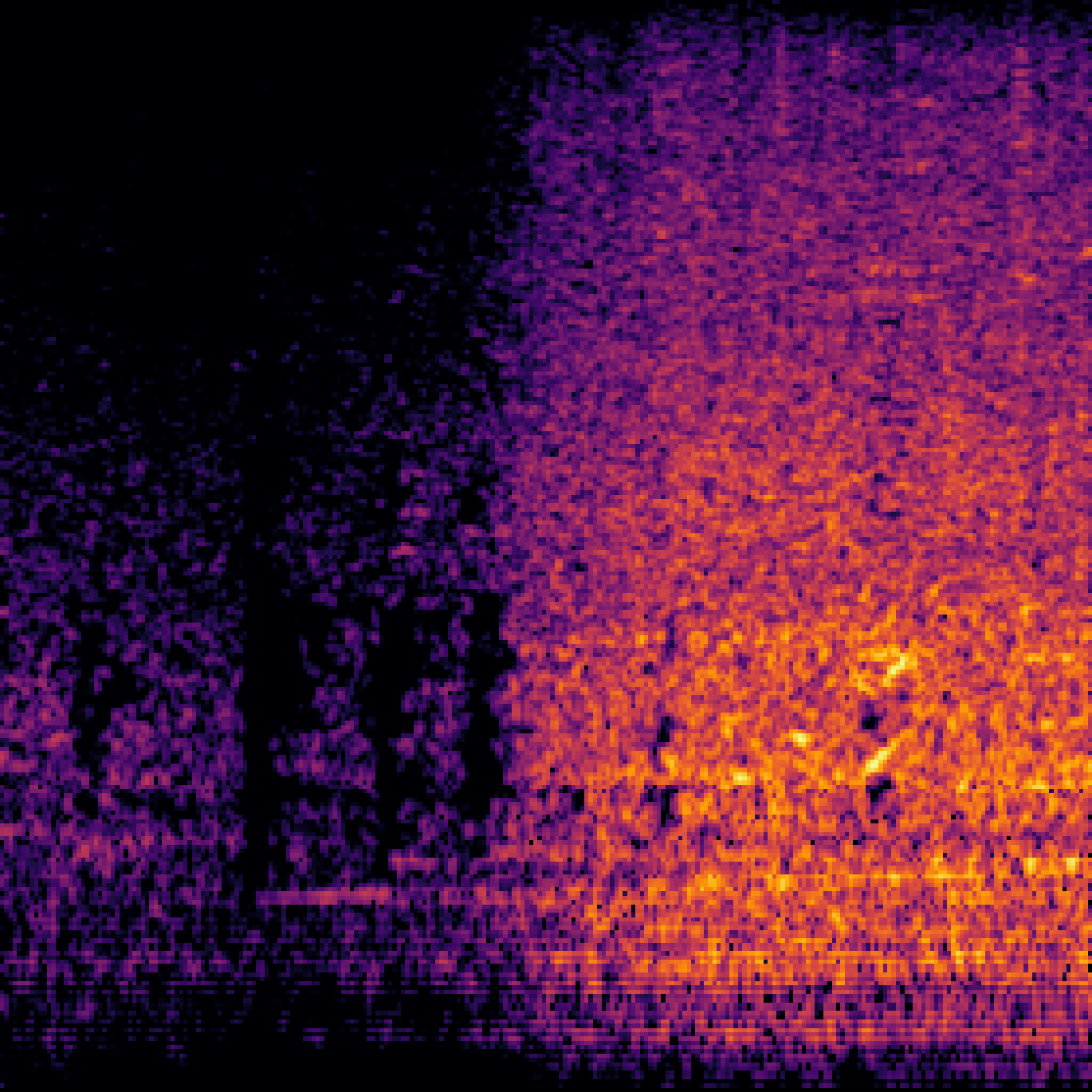
|
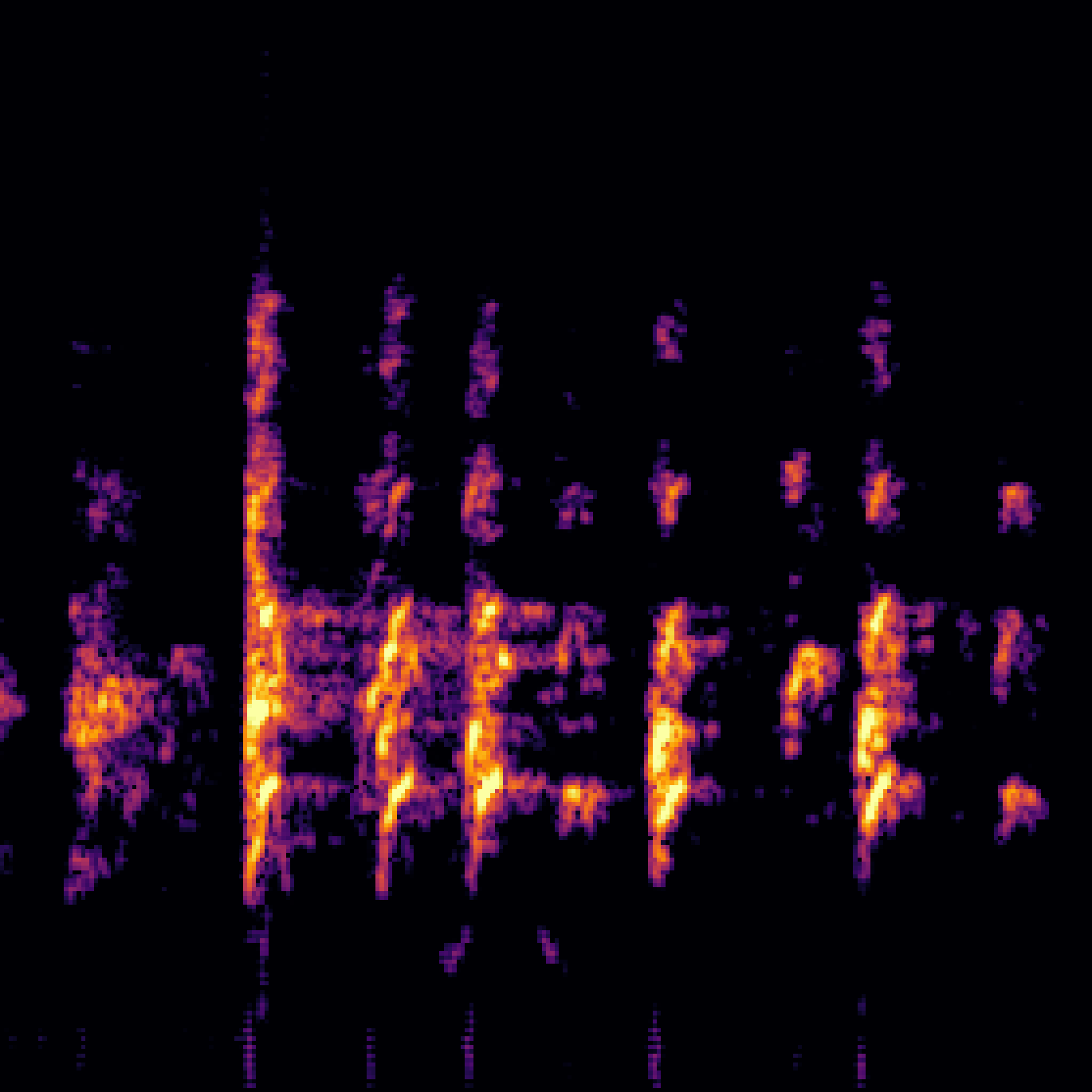
|
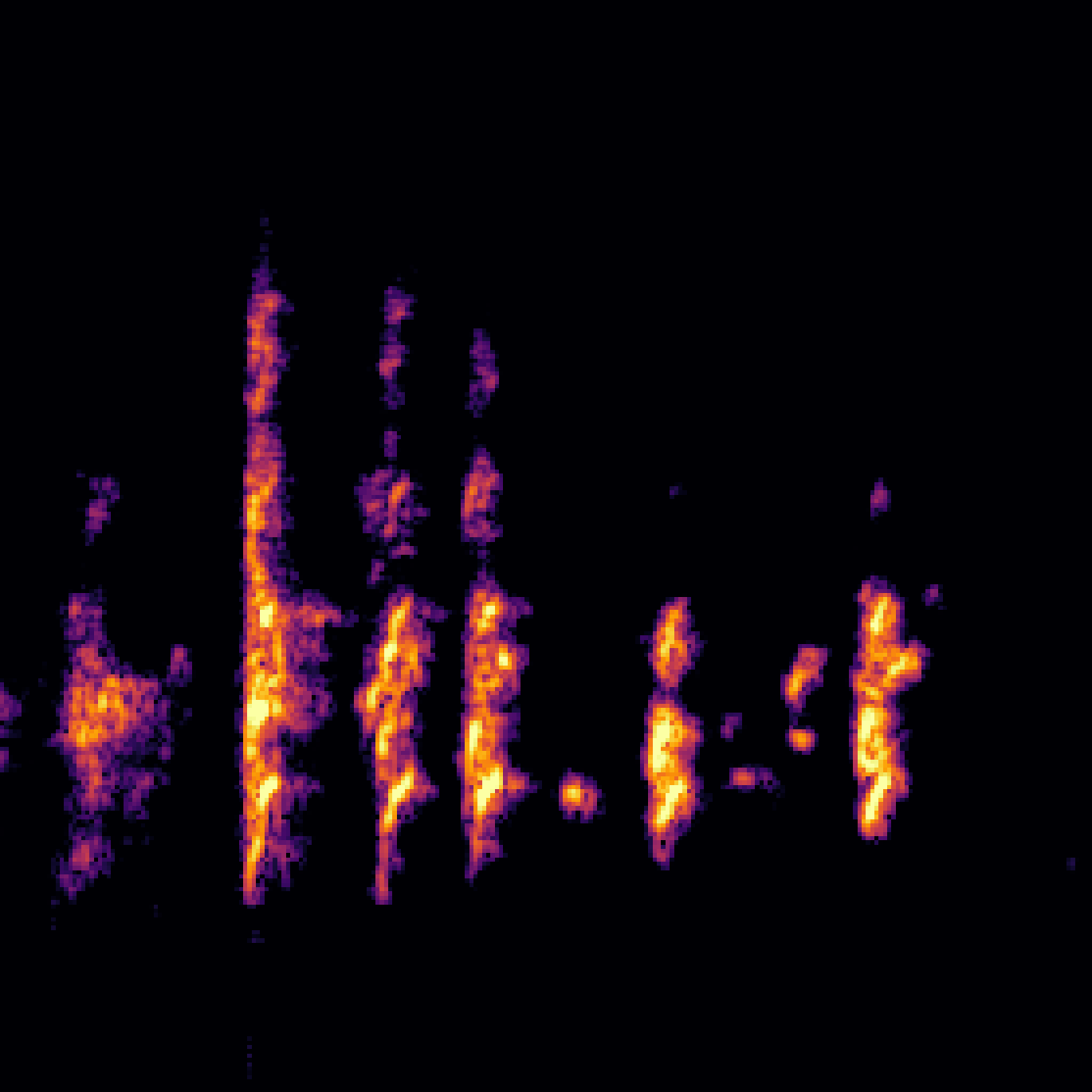
|
A.3.Audio-Query
| Query | Mixture | Interference | Target | Prediction |
|---|---|---|---|---|
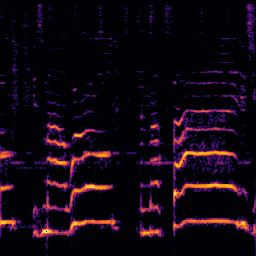
|
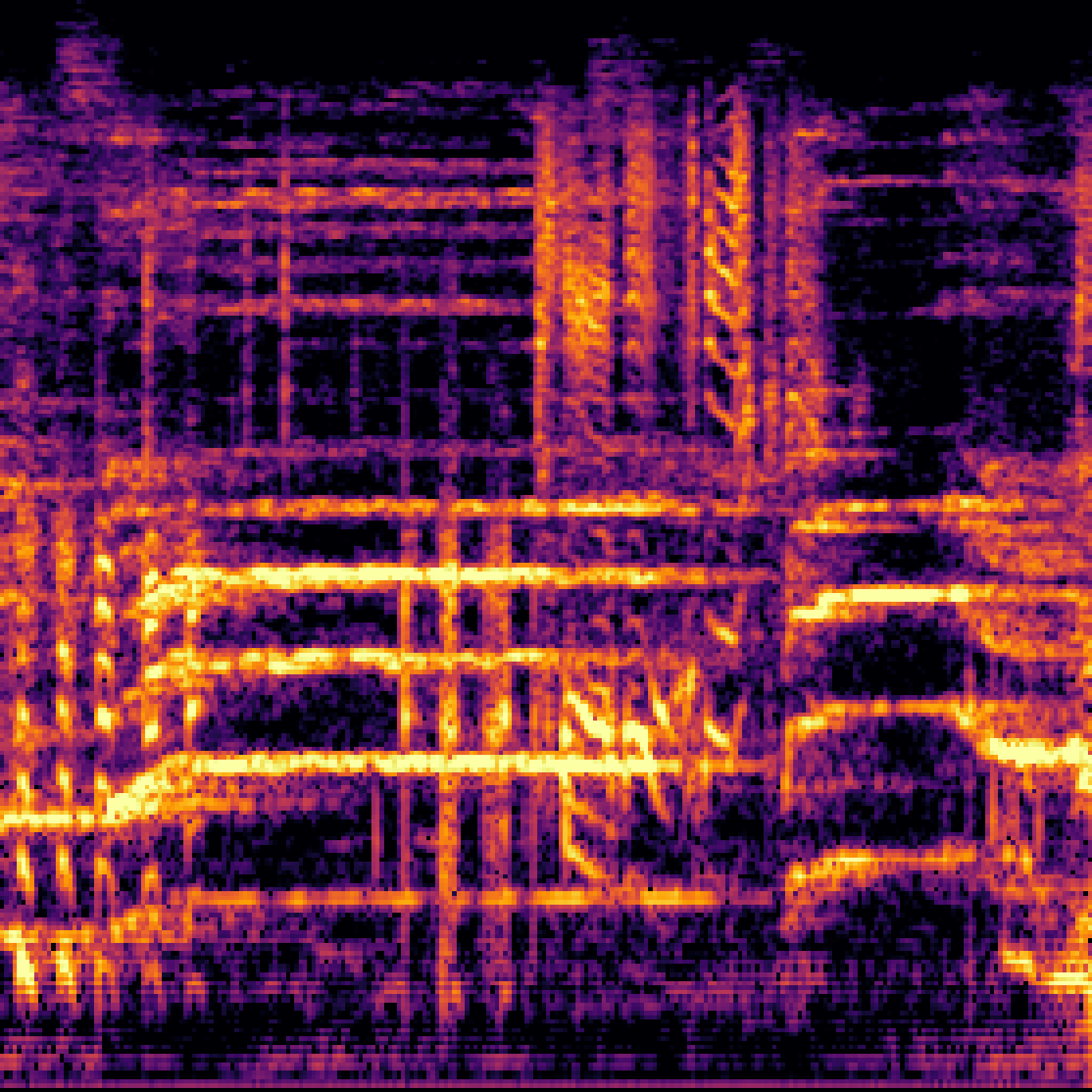
|
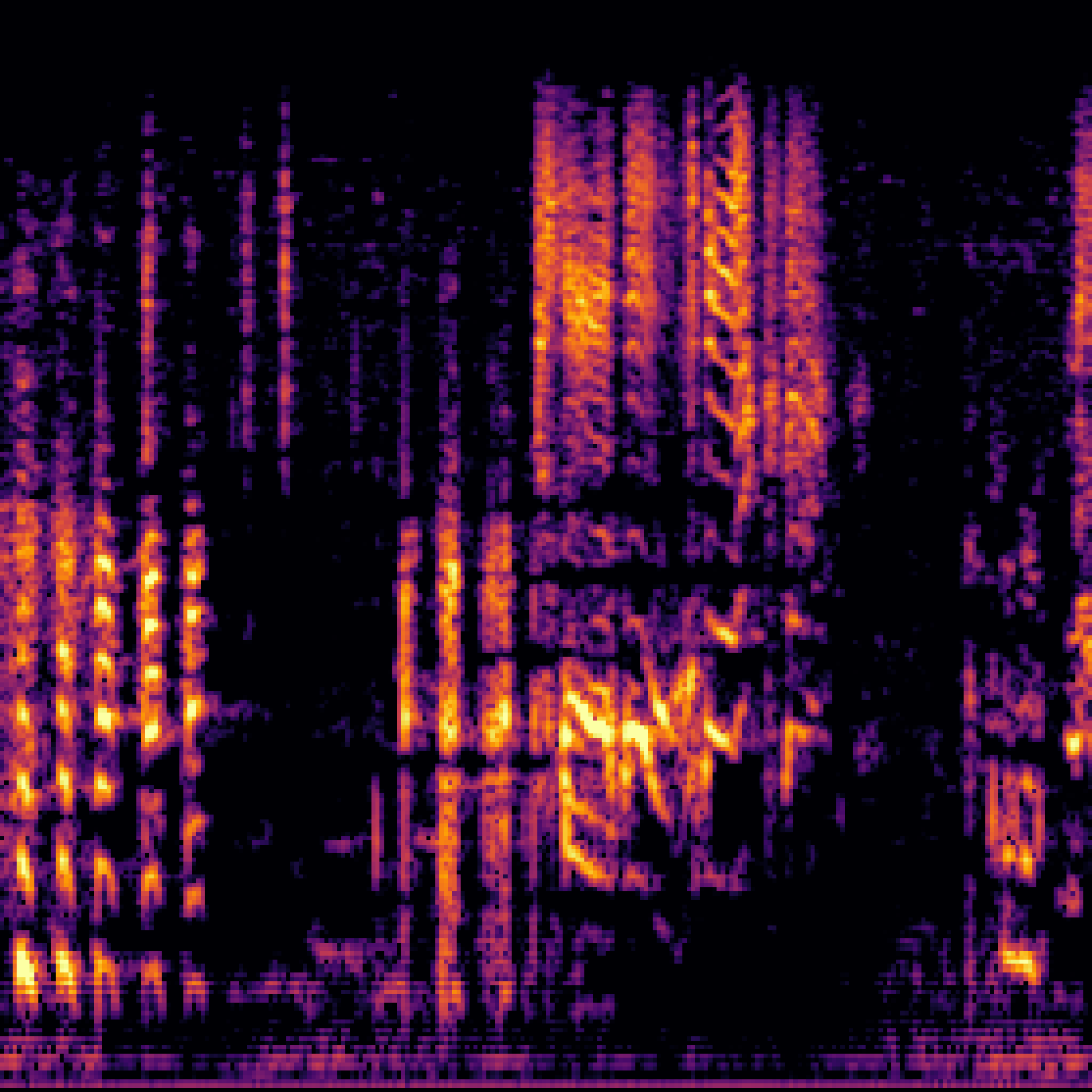
|
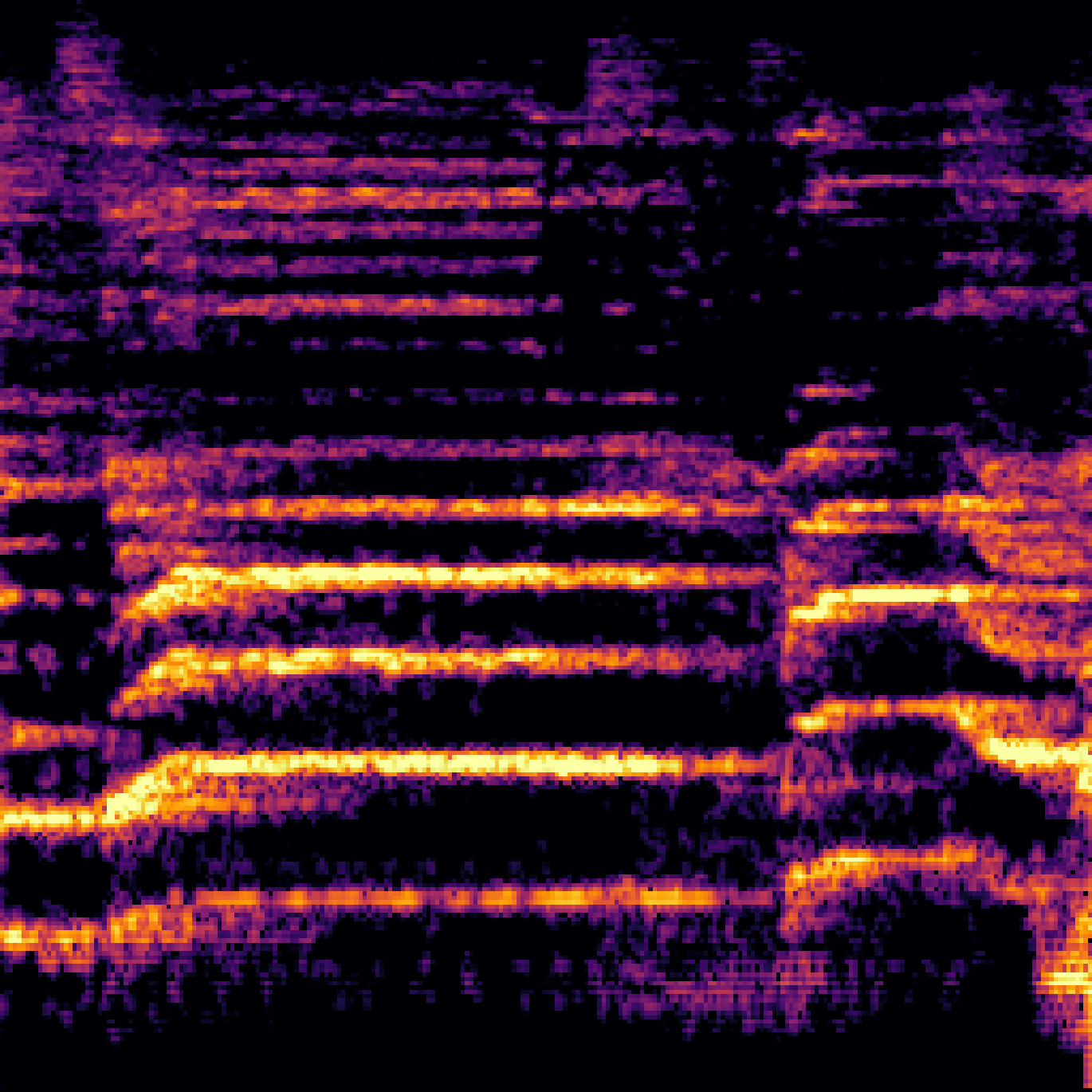
|
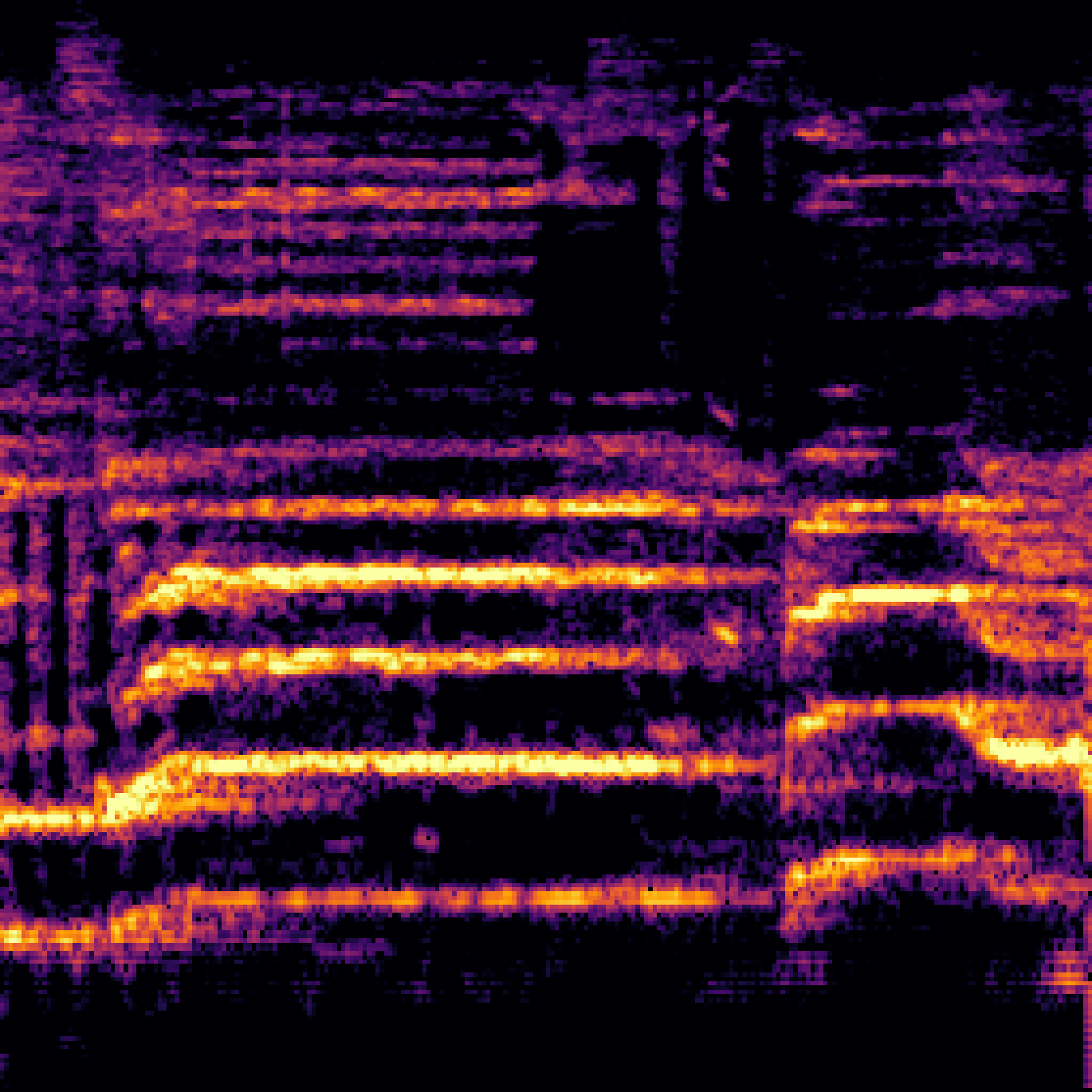
|
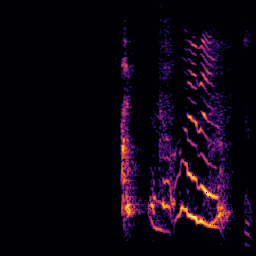
|
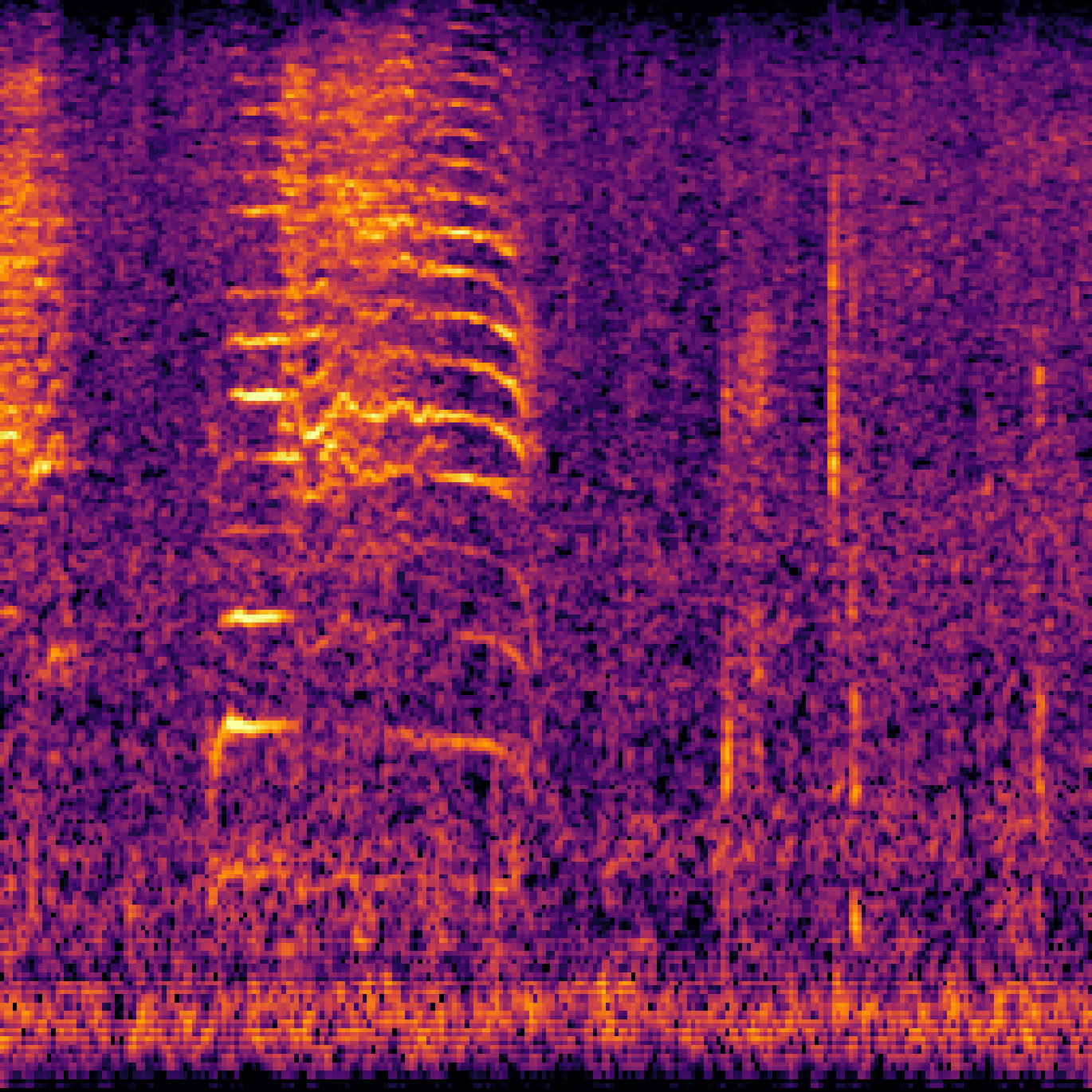
|
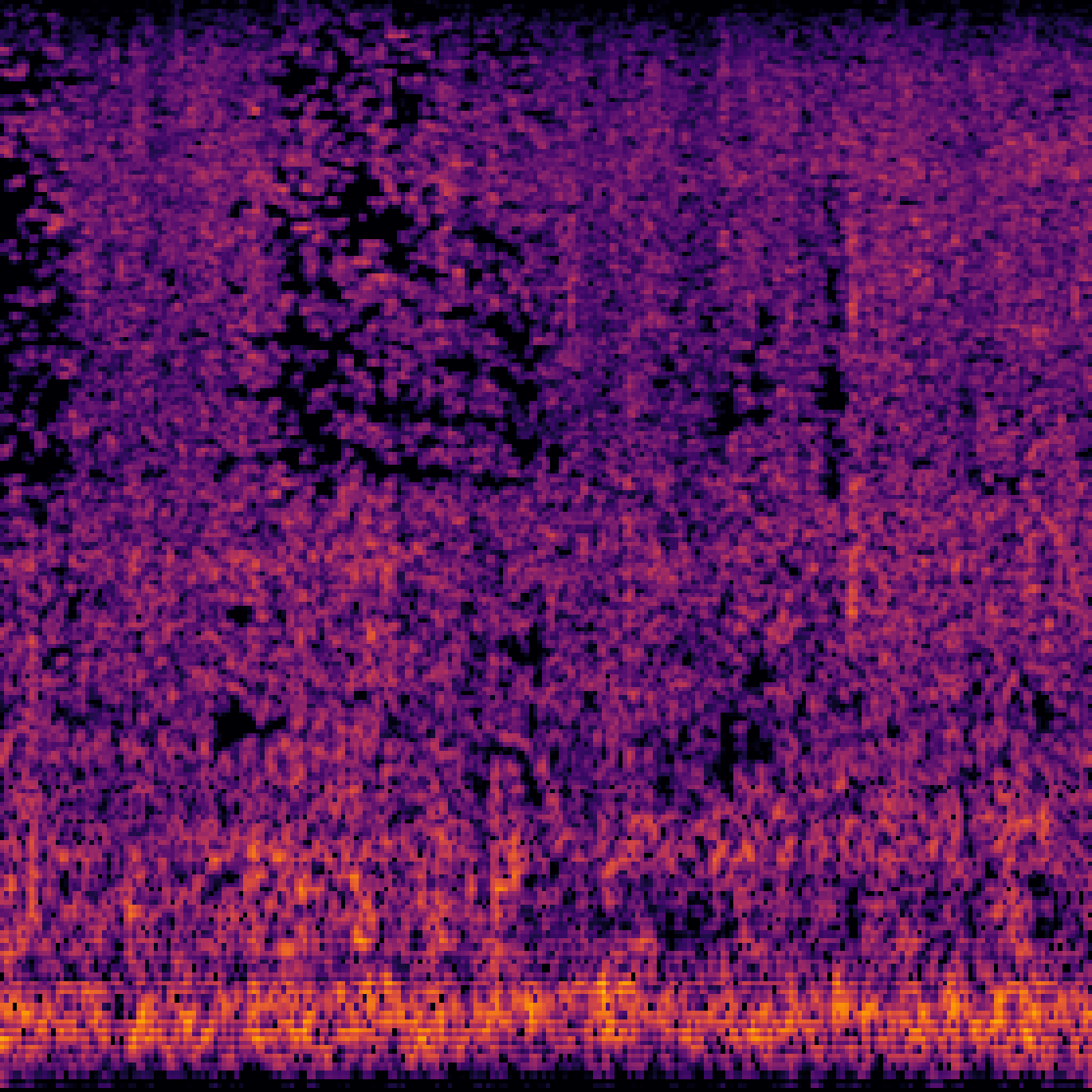
|
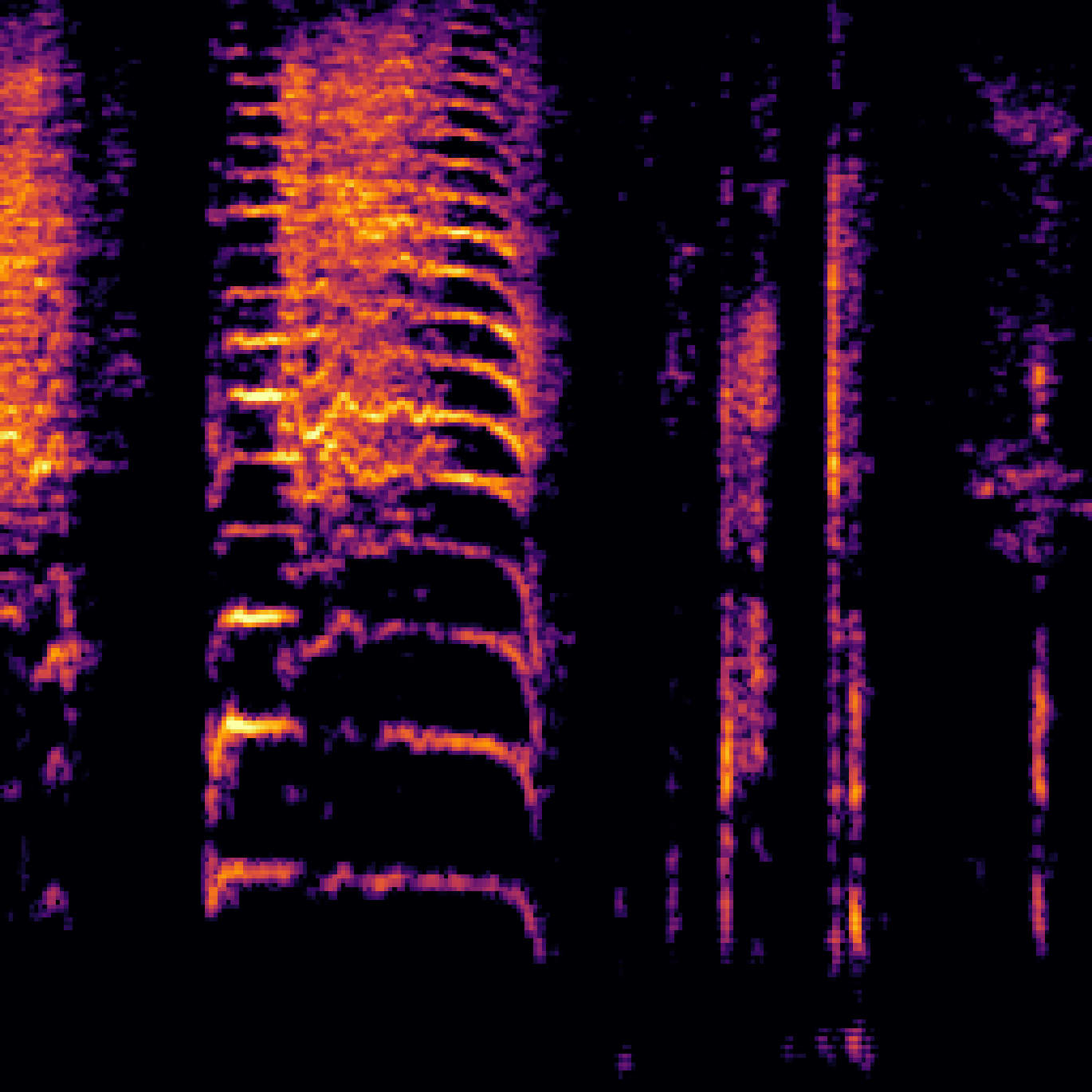
|
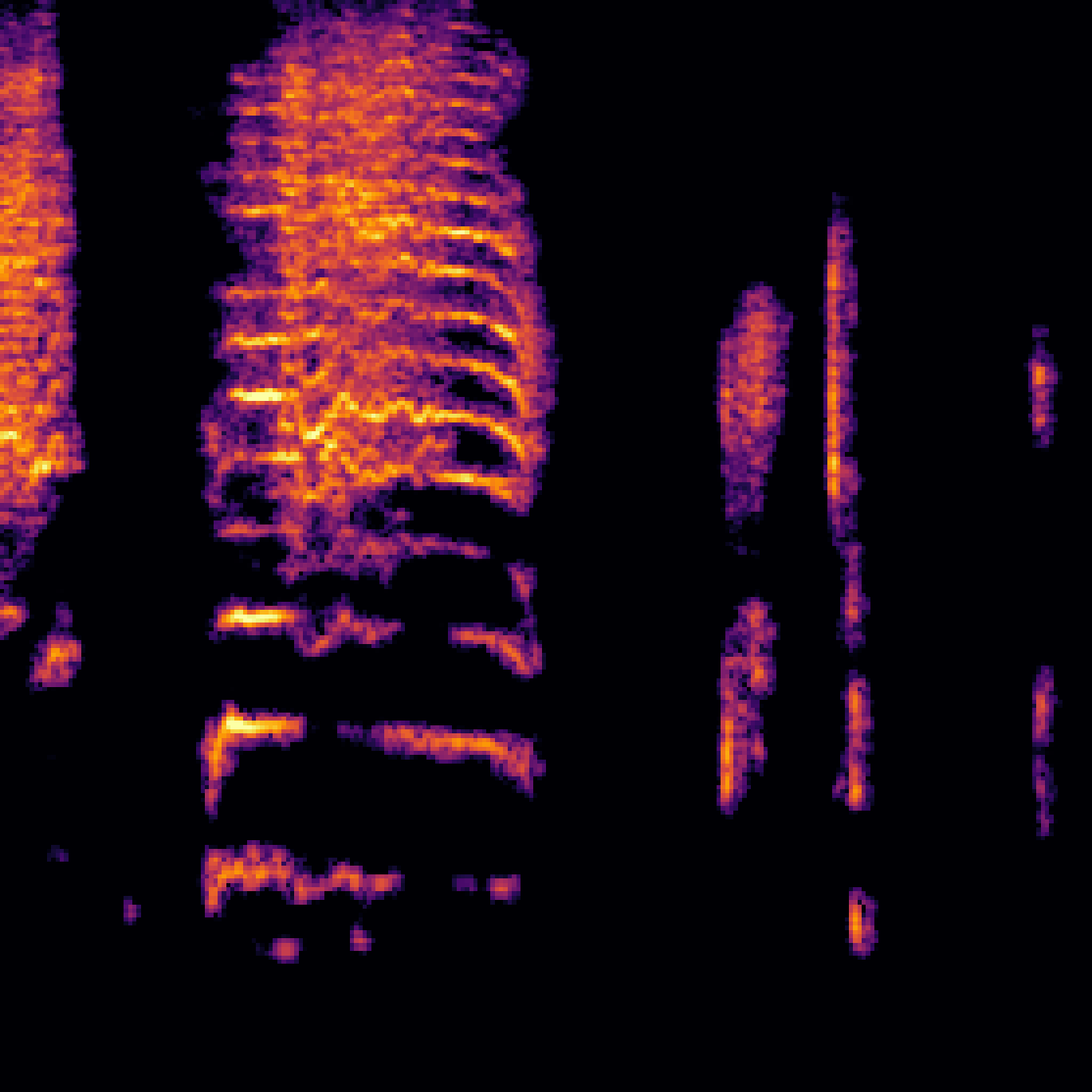
|
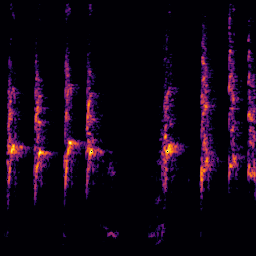
|
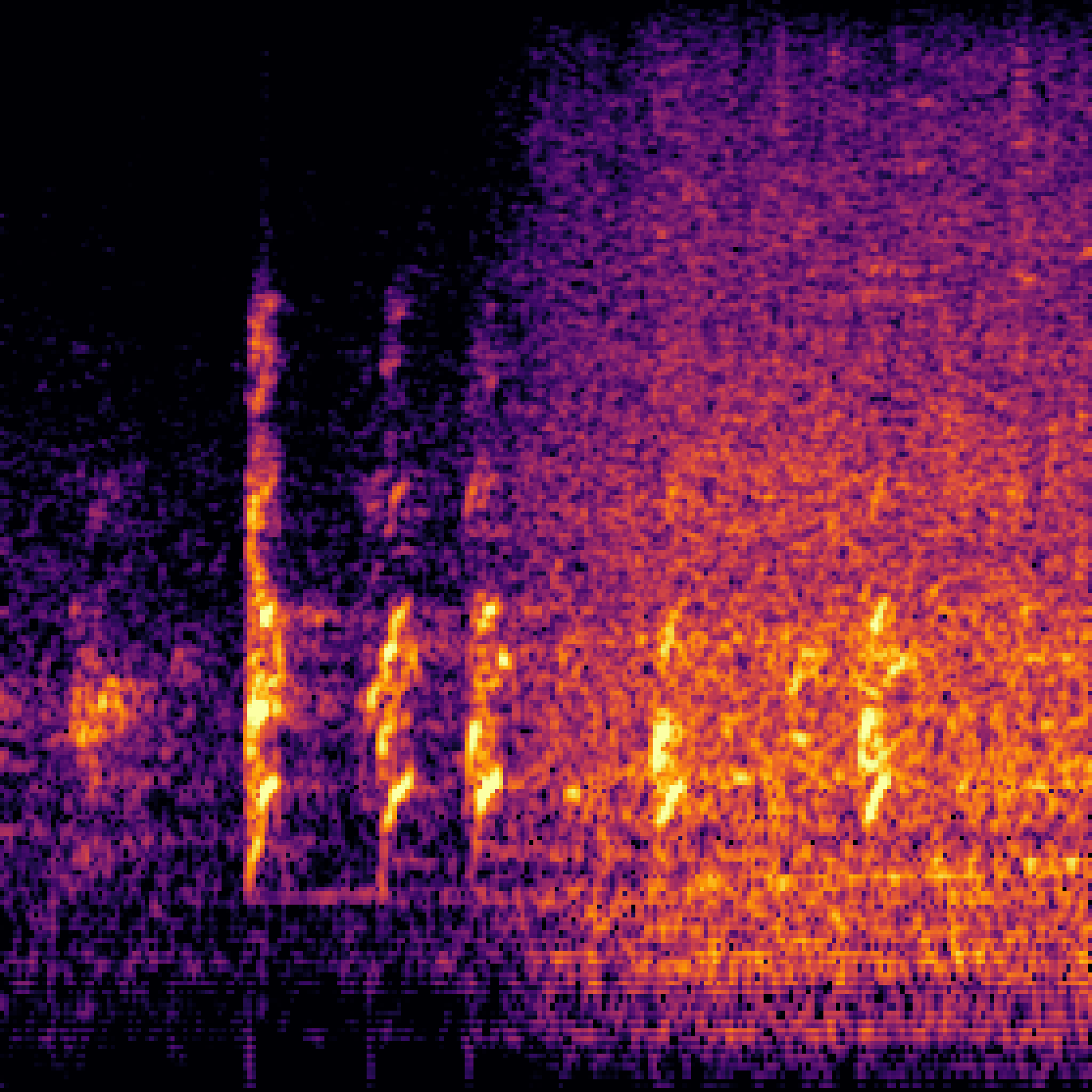
|
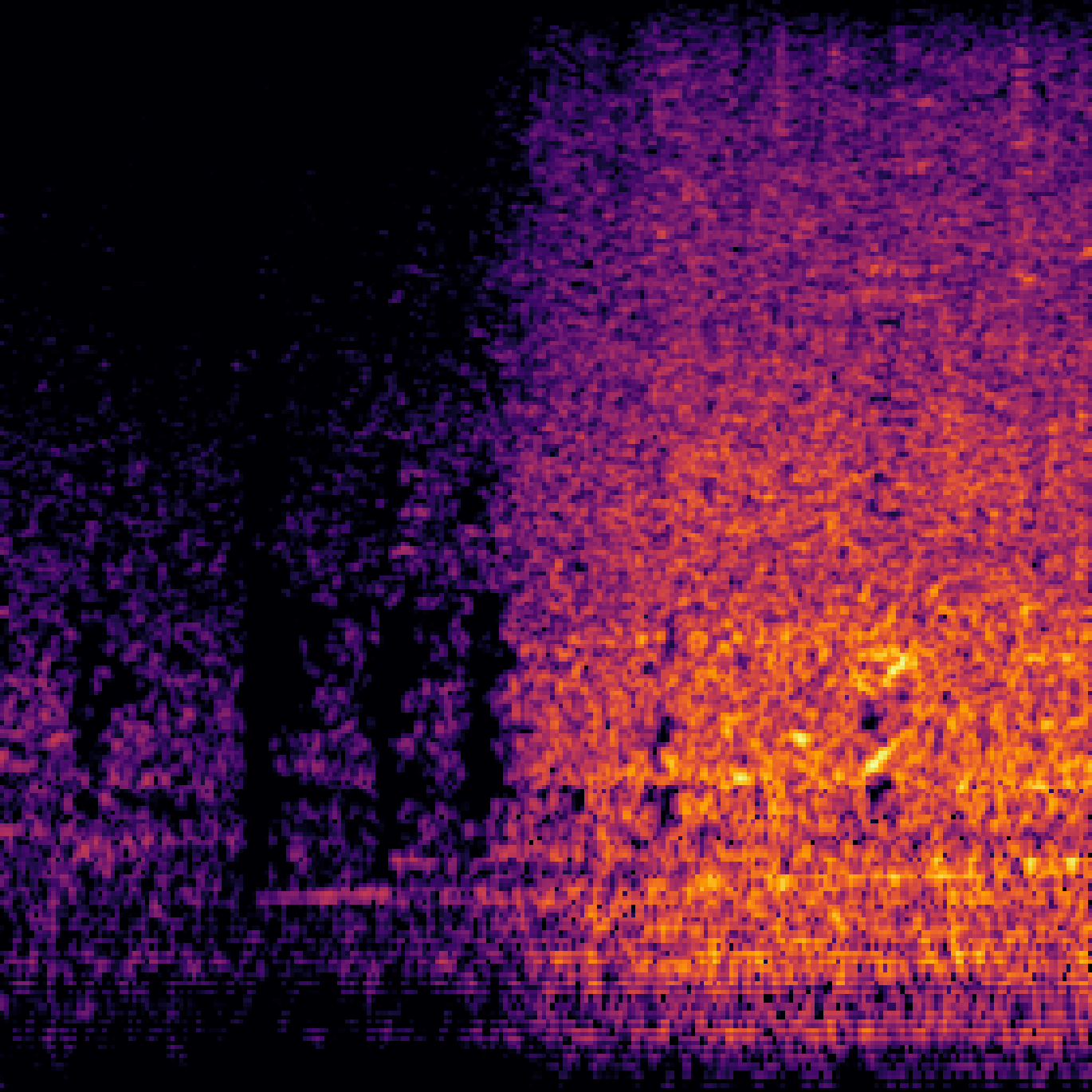
|
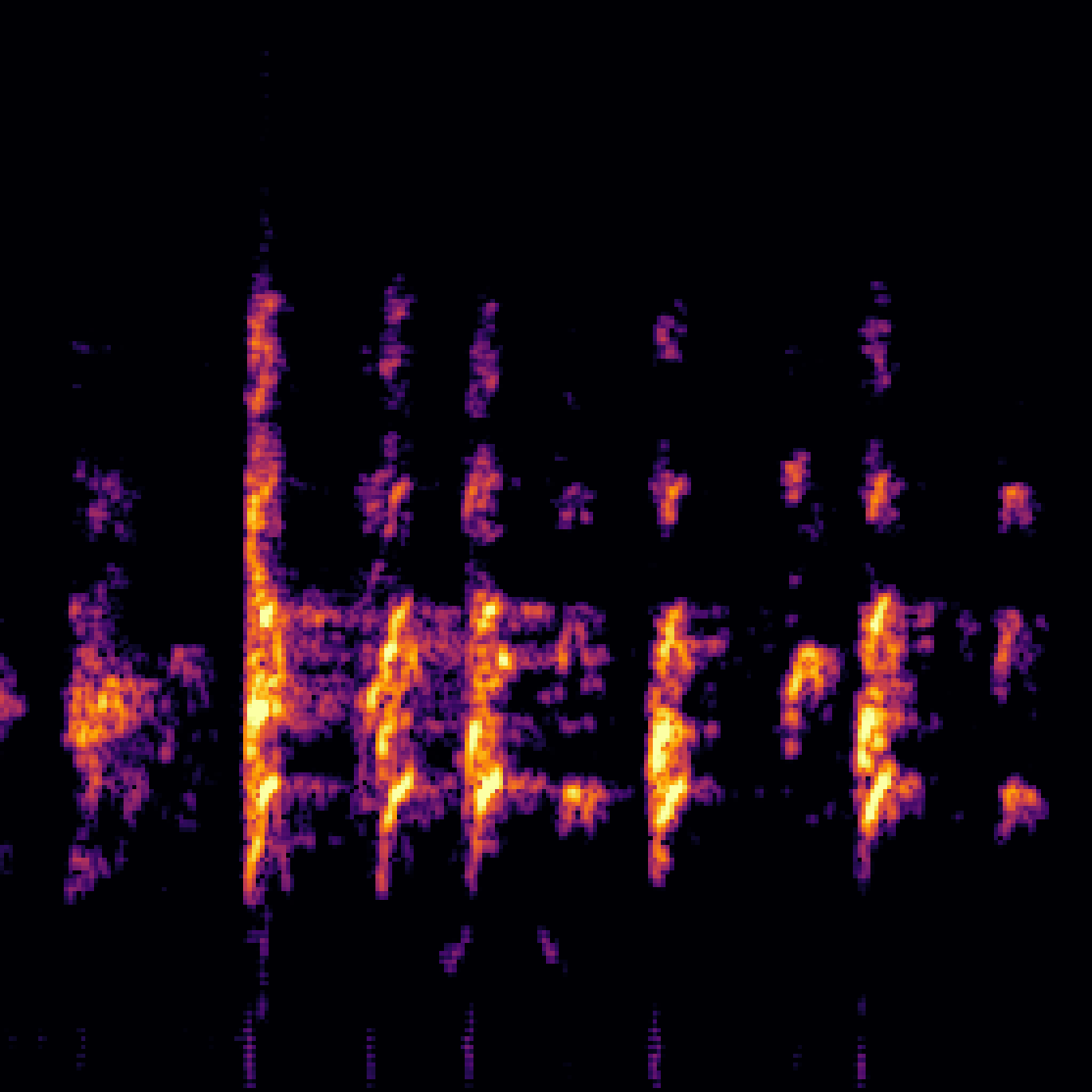
|
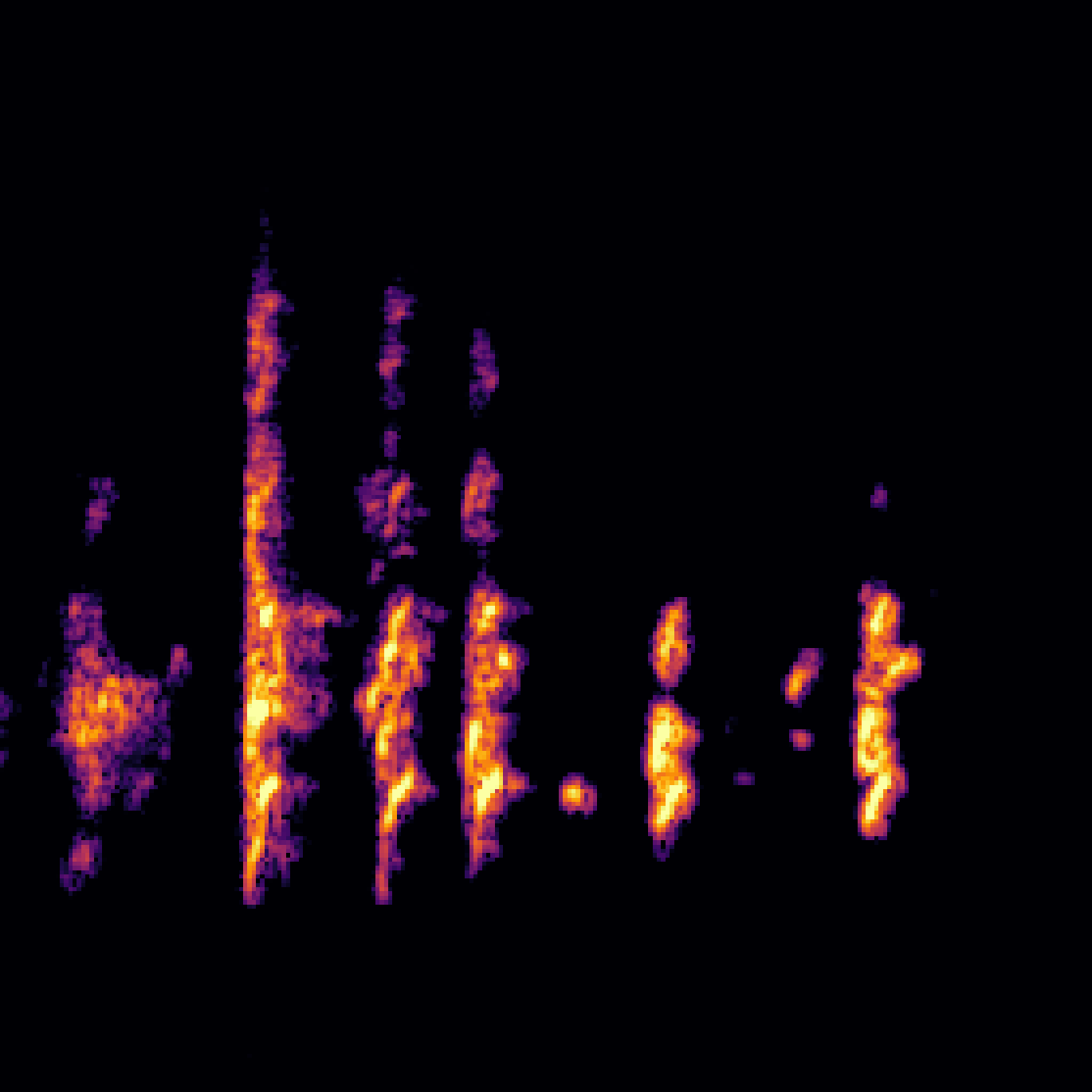
|
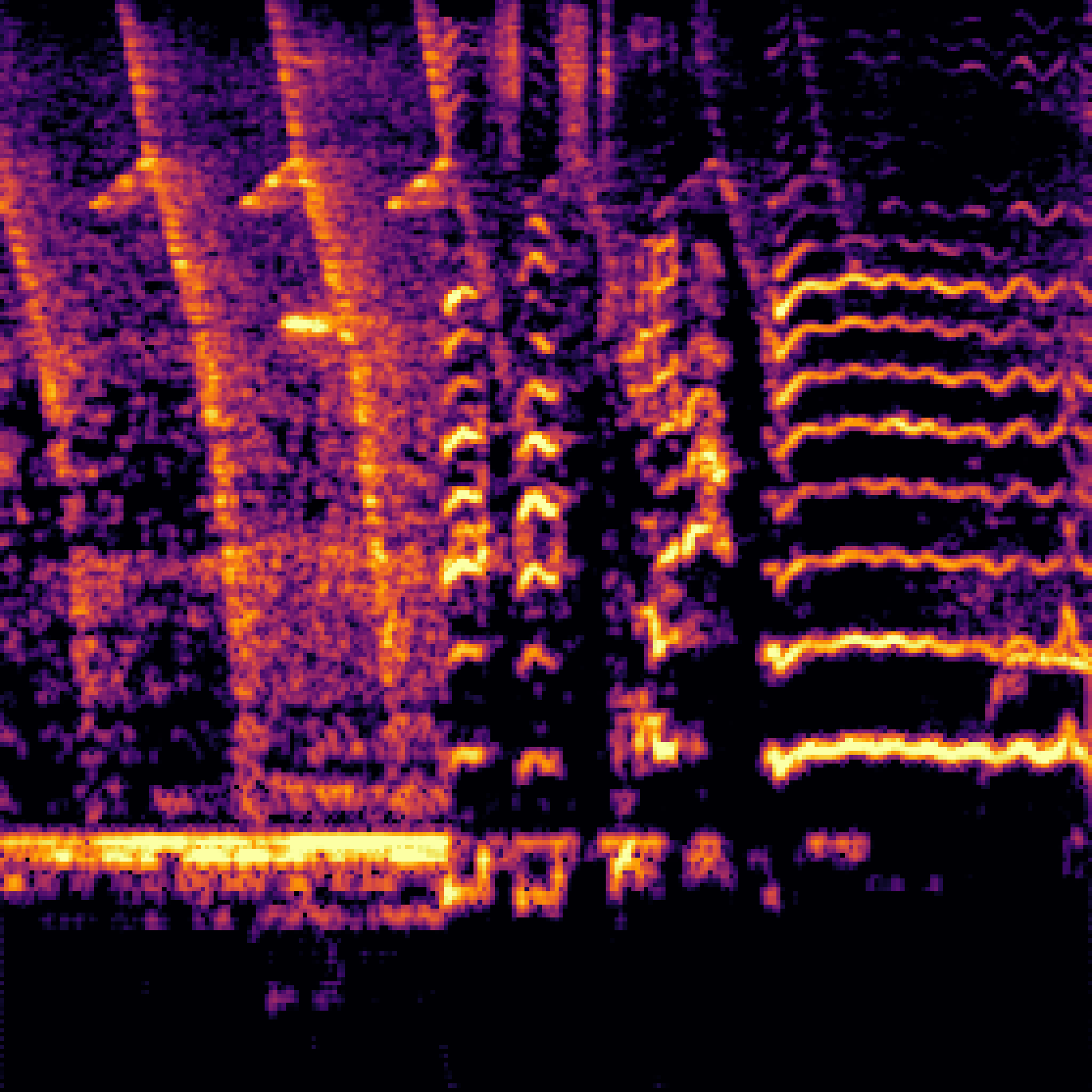
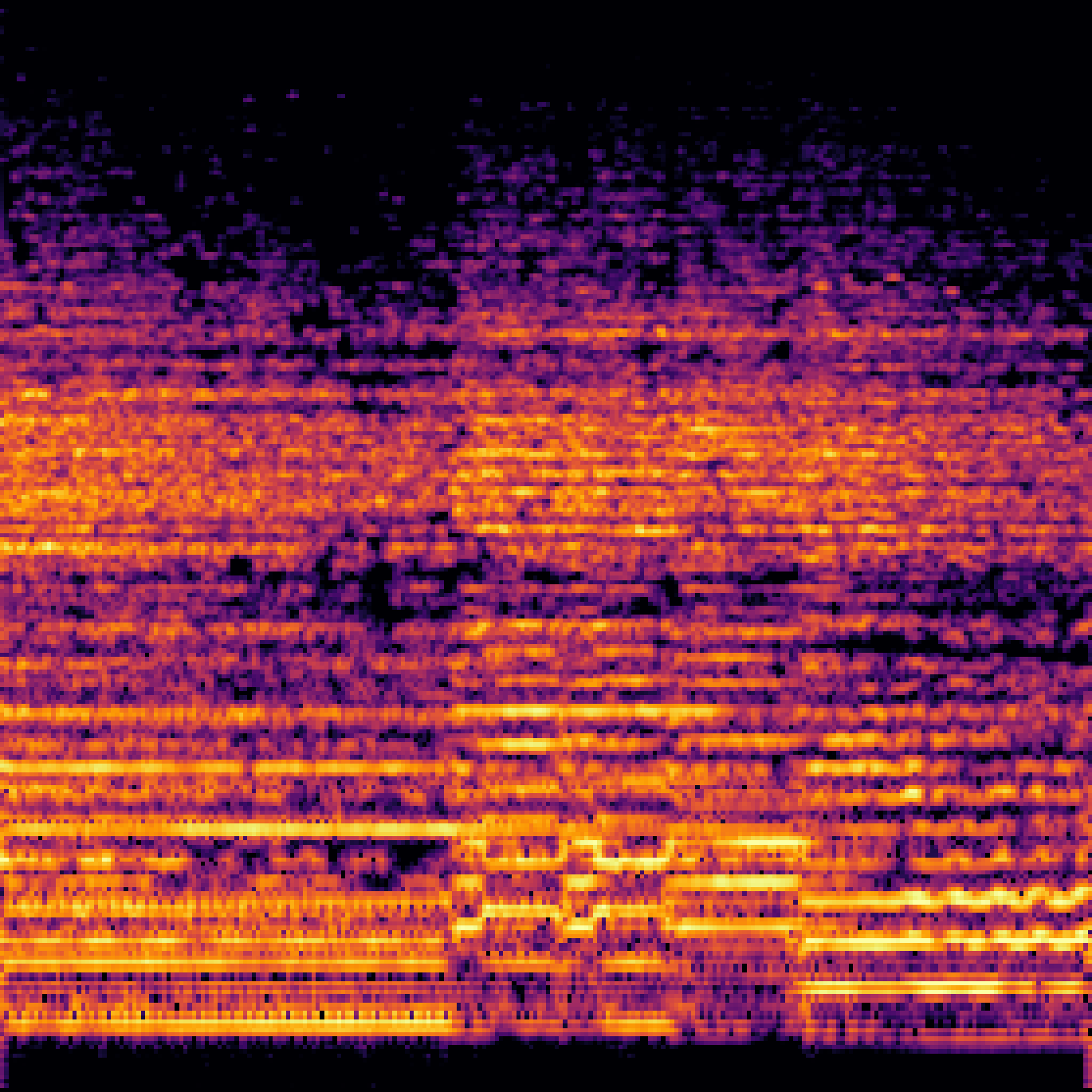
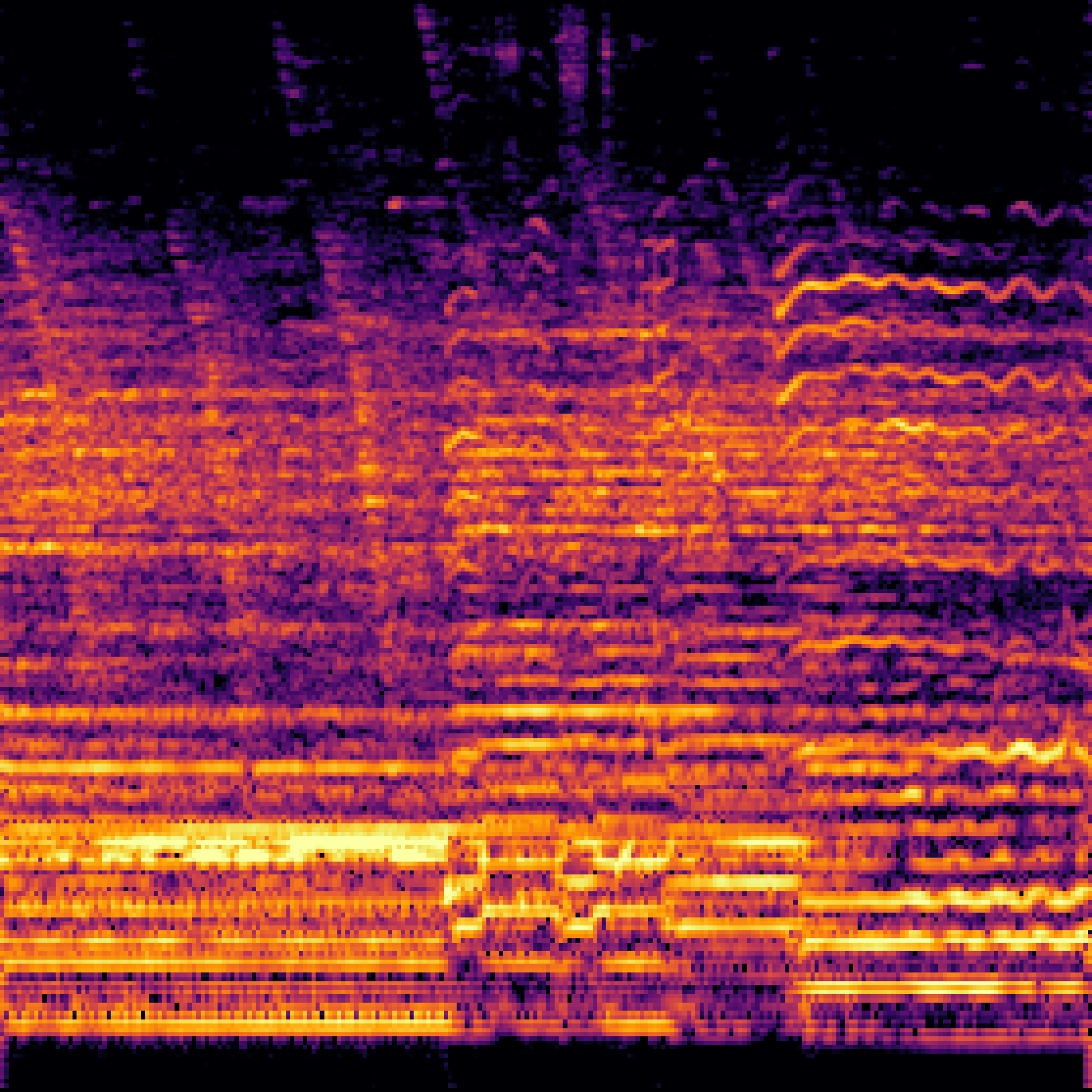
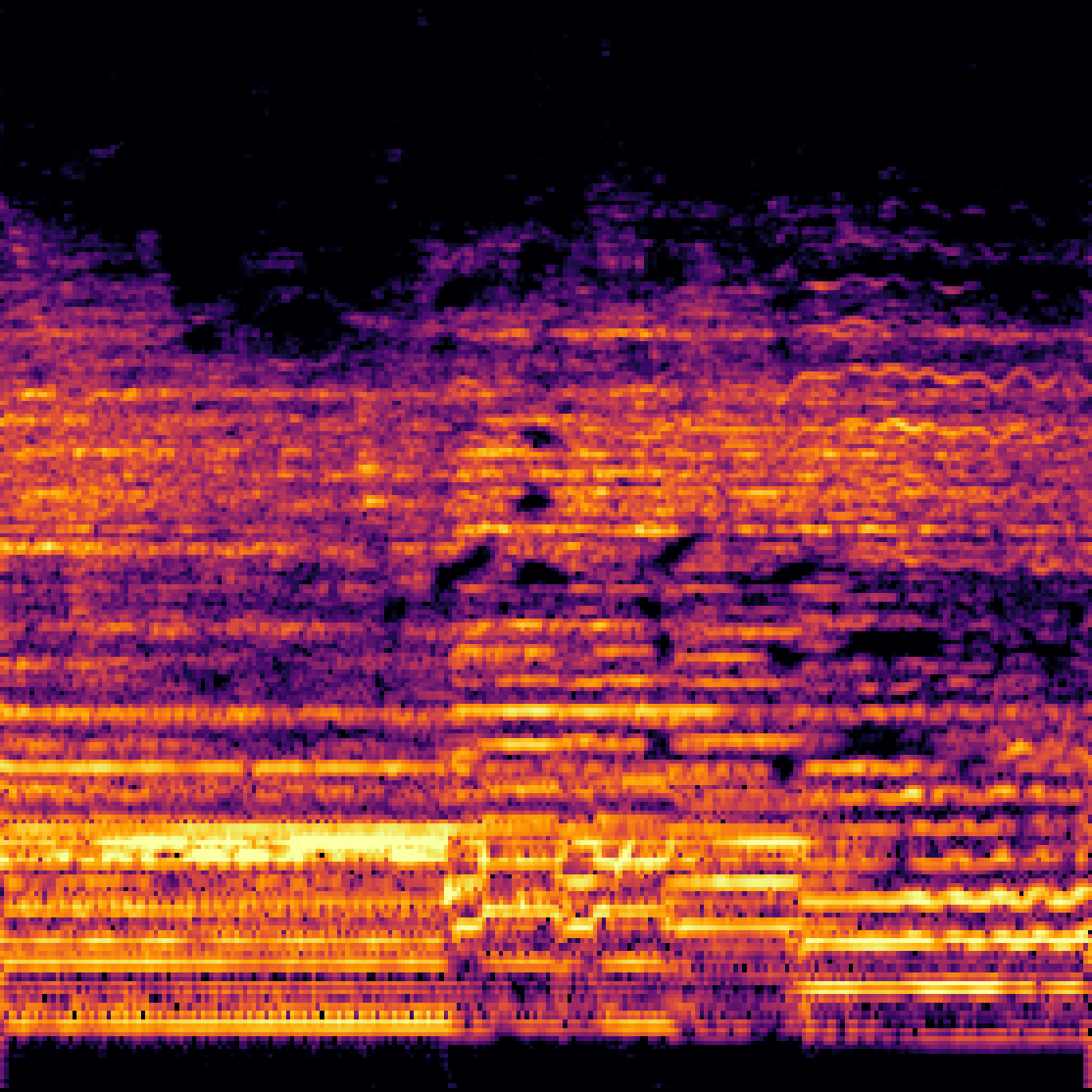
B.Sound Separation with Negative Queries.
| Mixture | Interference | Target | OmniSEP | OmniSEP+Neg |
|---|---|---|---|---|
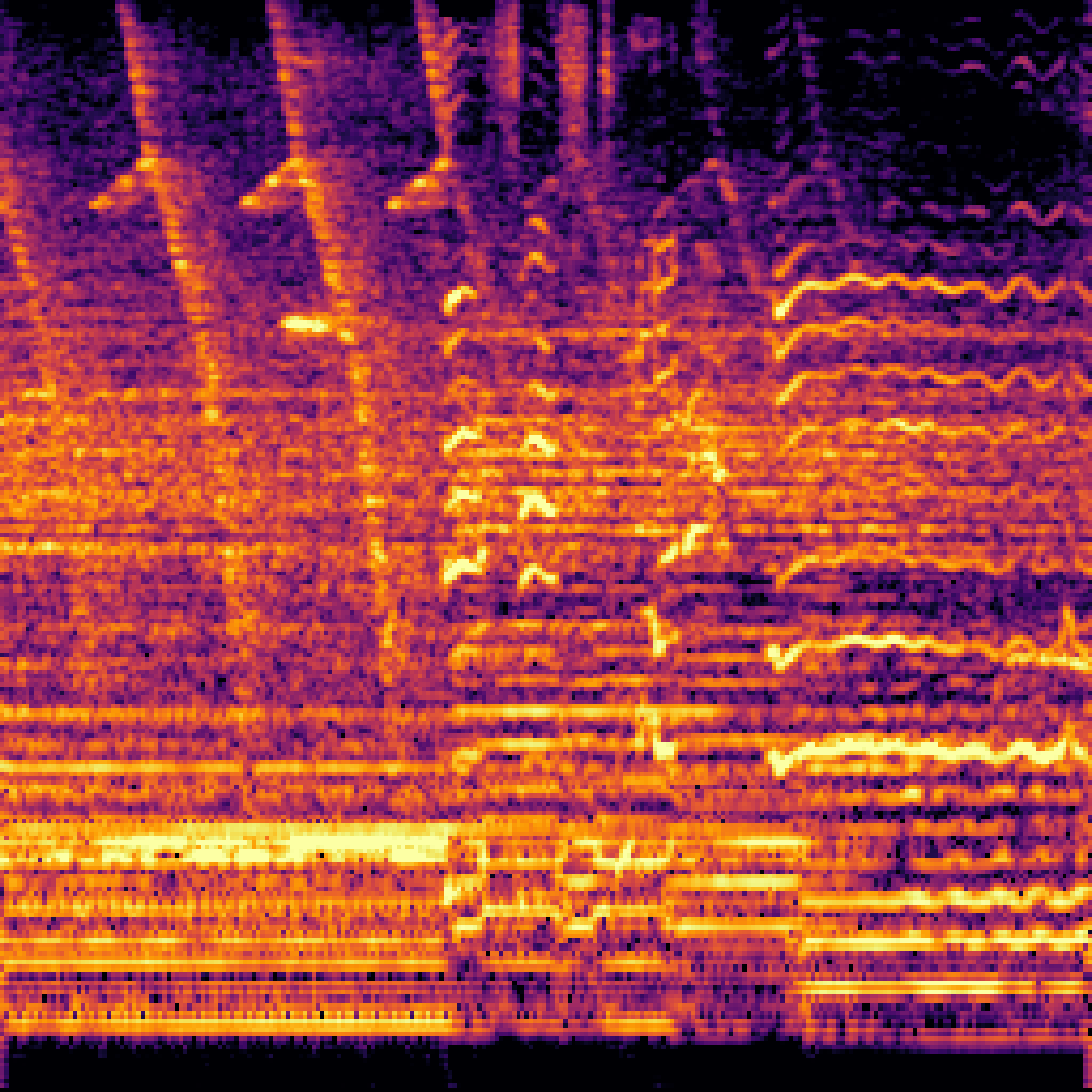
|
|
|
|
|
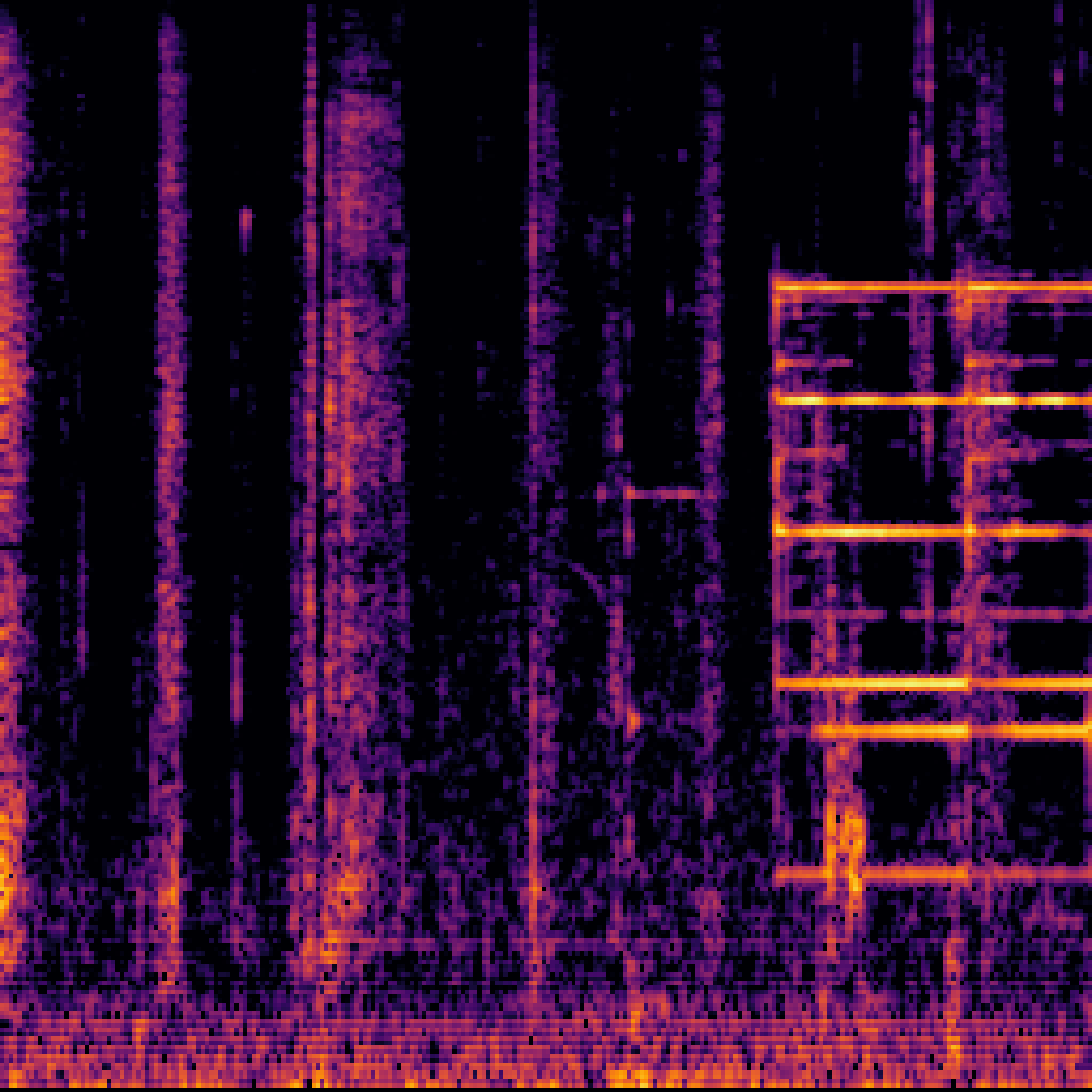
|
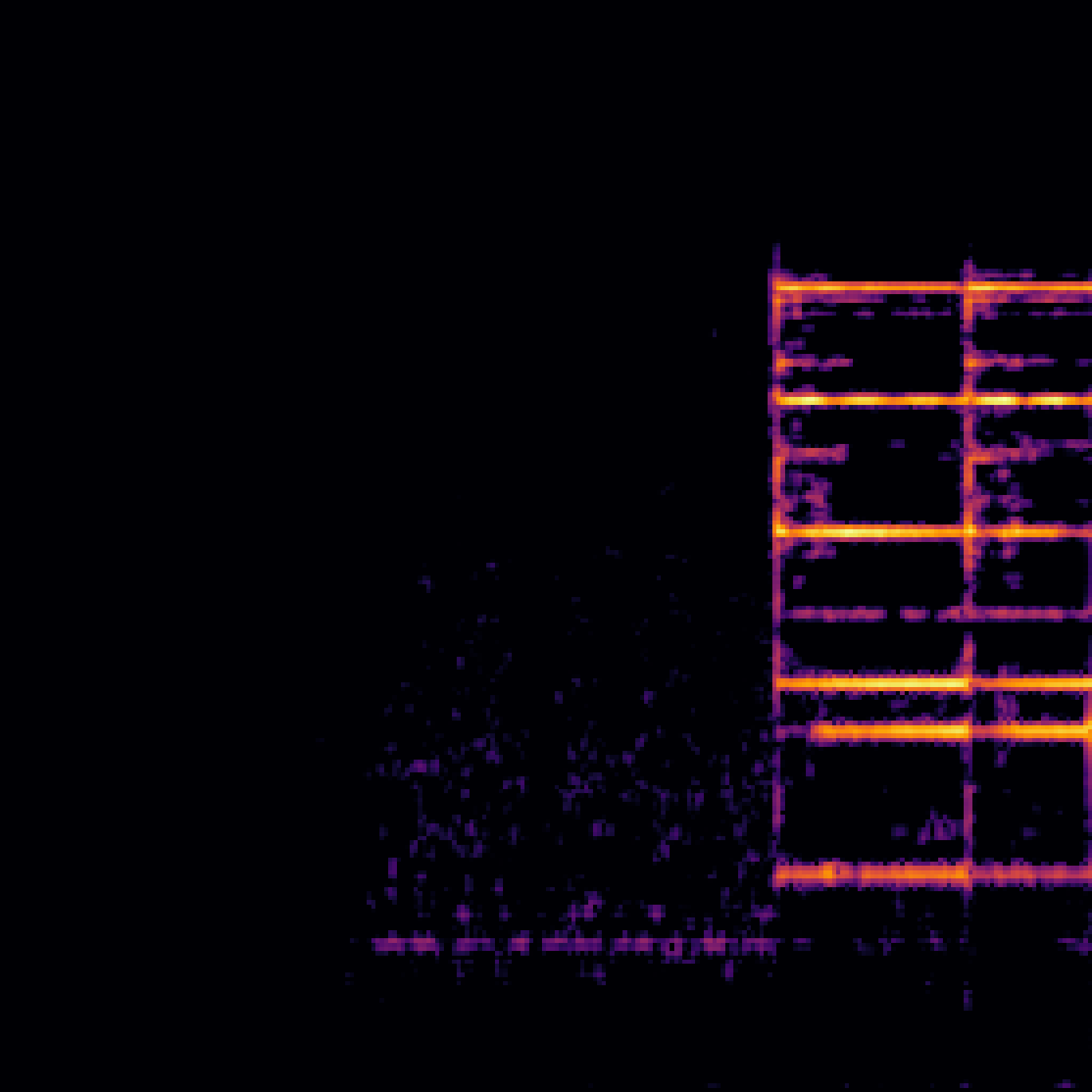
|
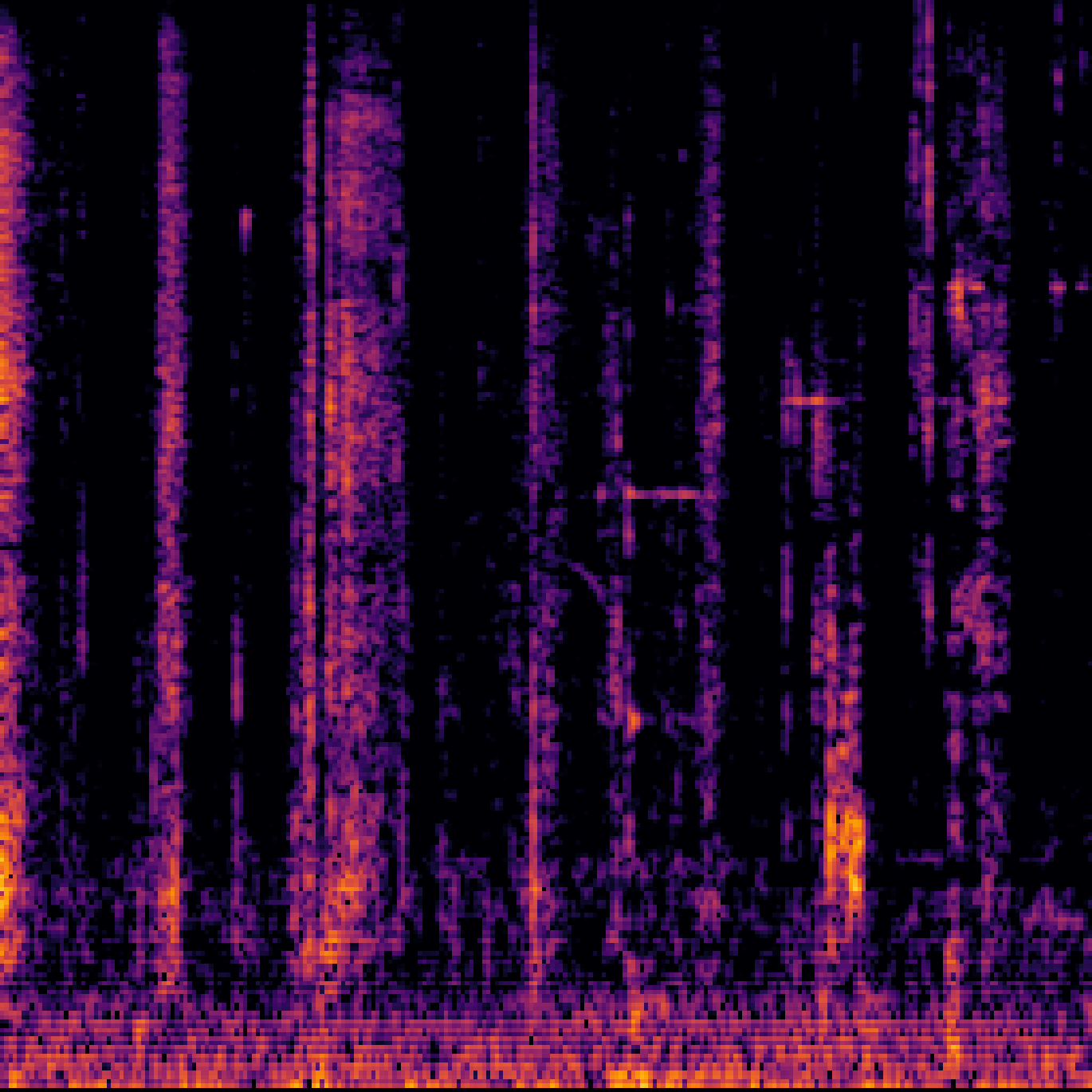
|
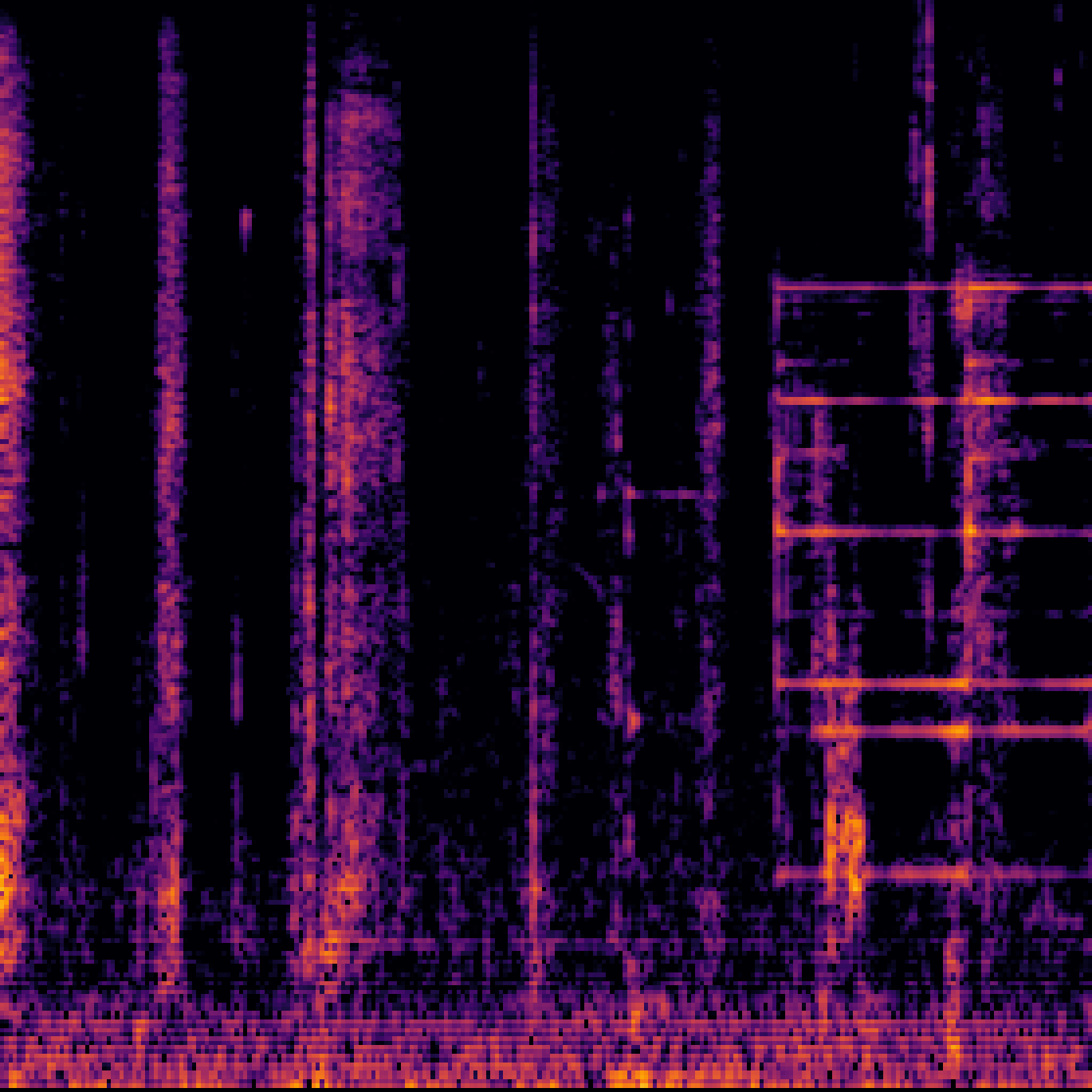
|
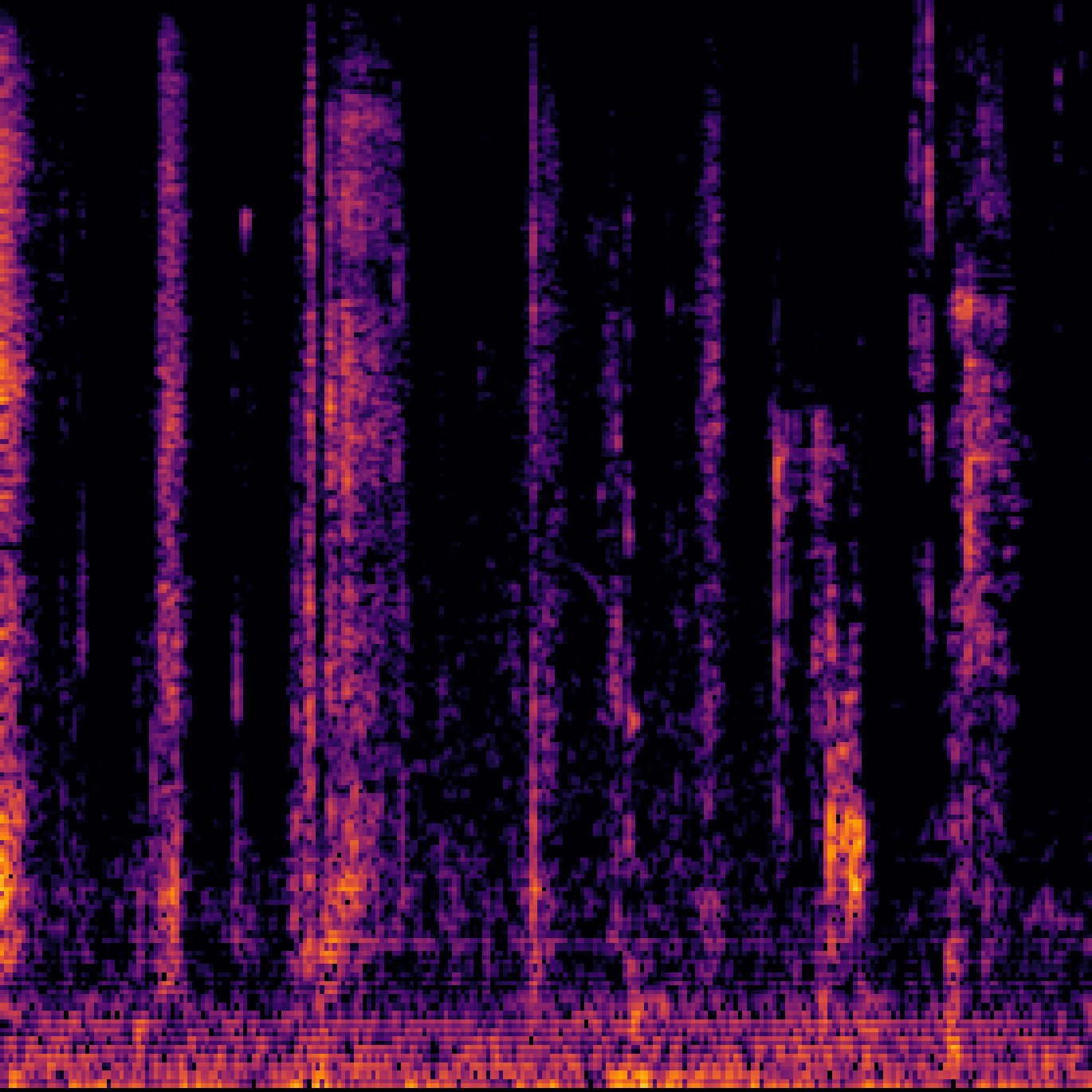
|
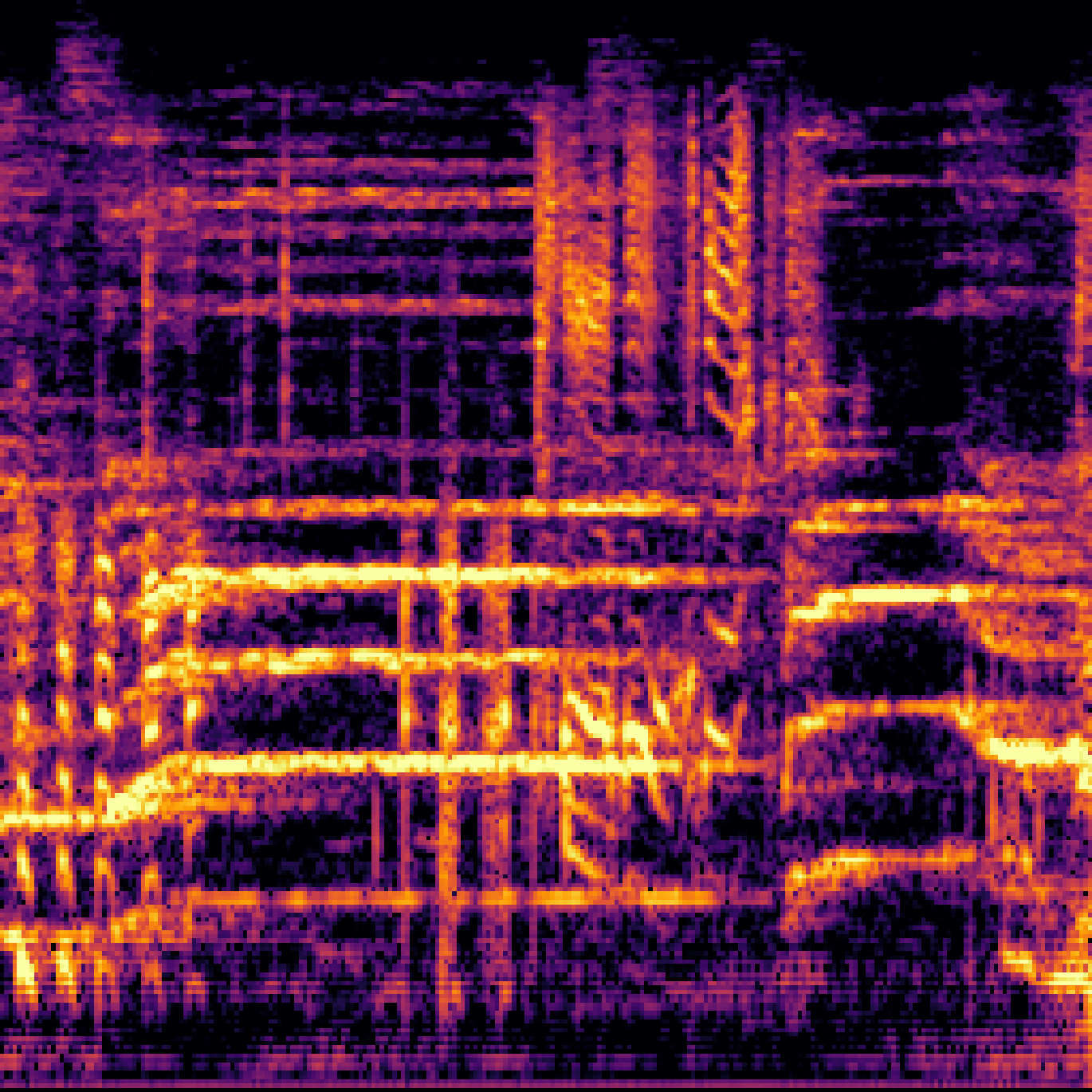
|
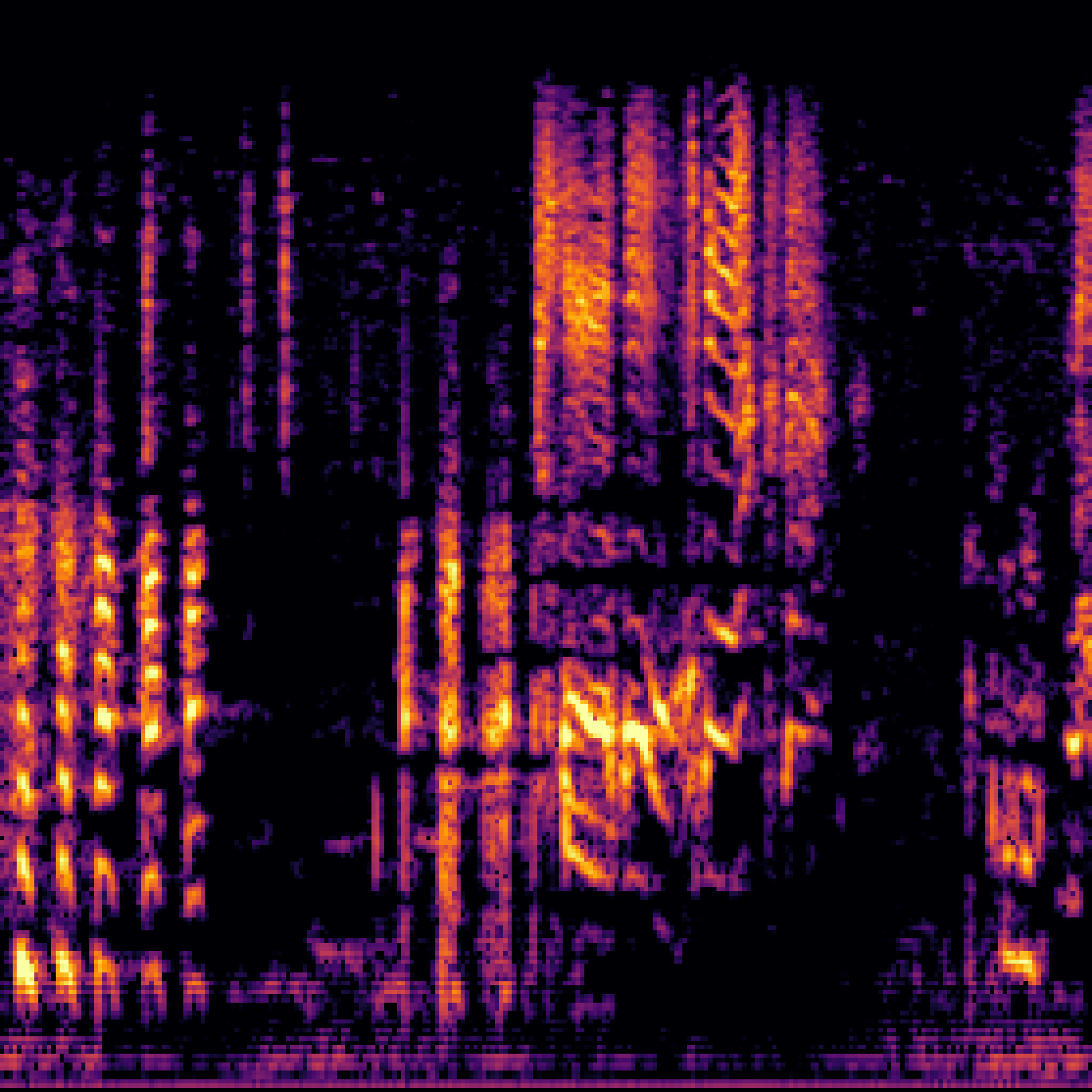
|
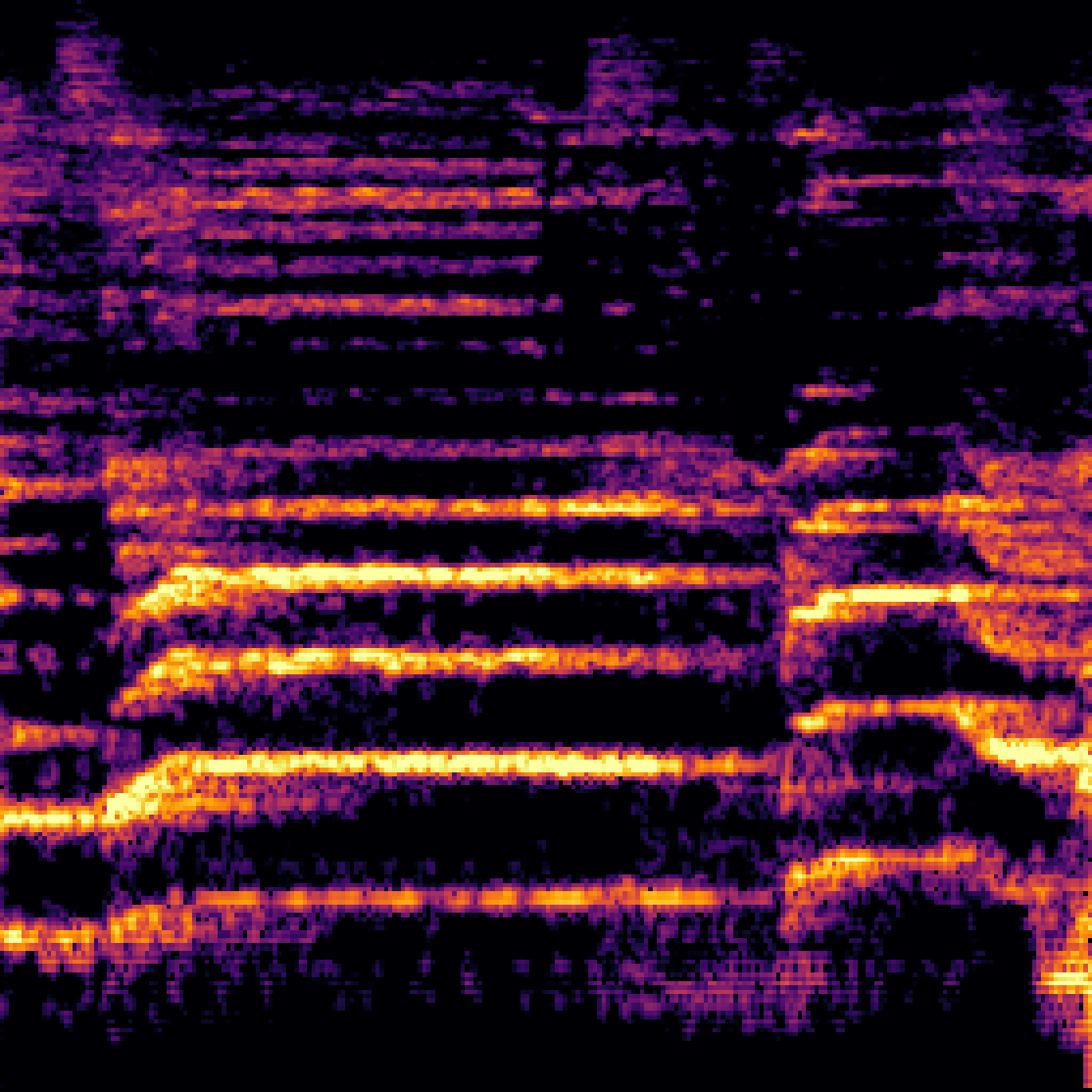
|
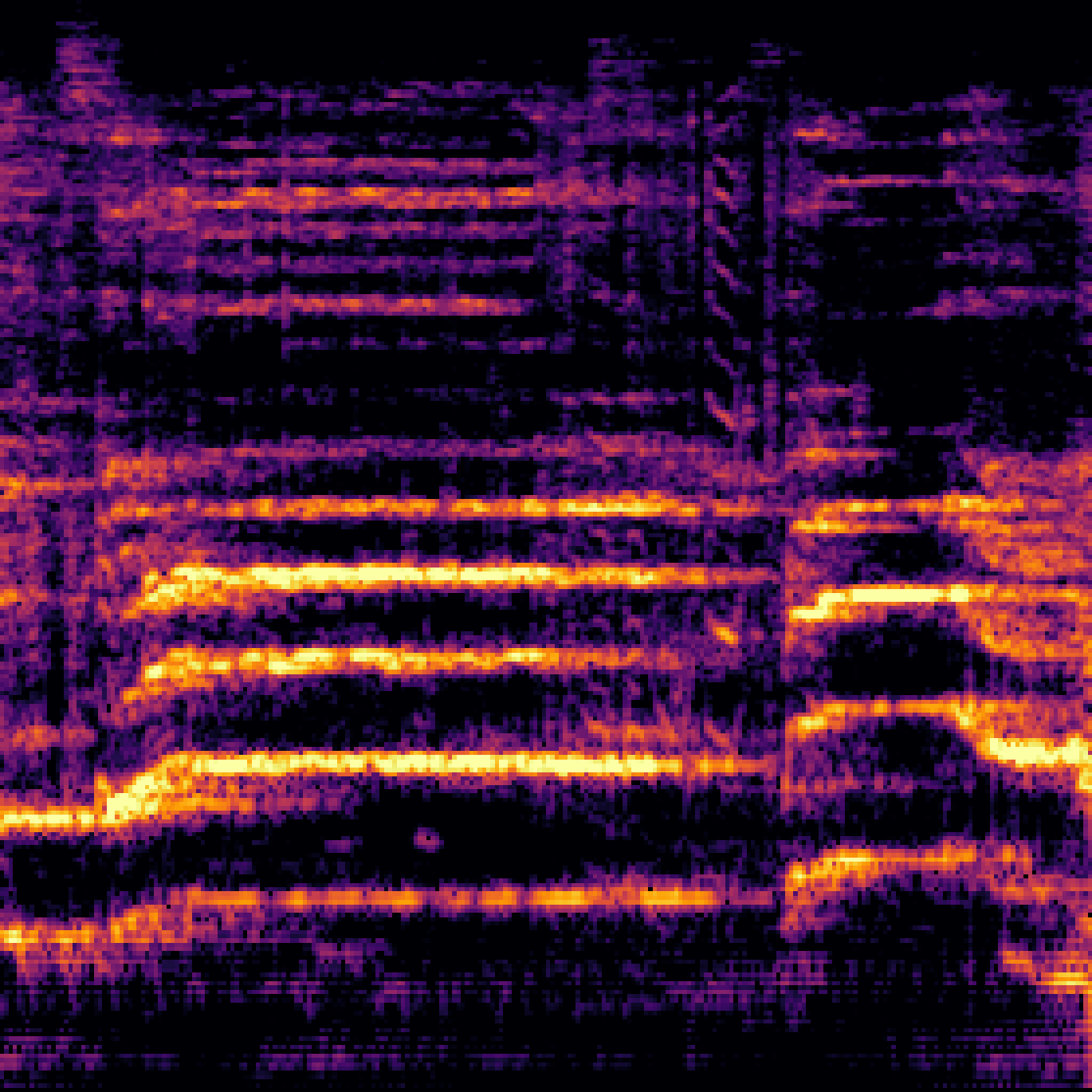
|
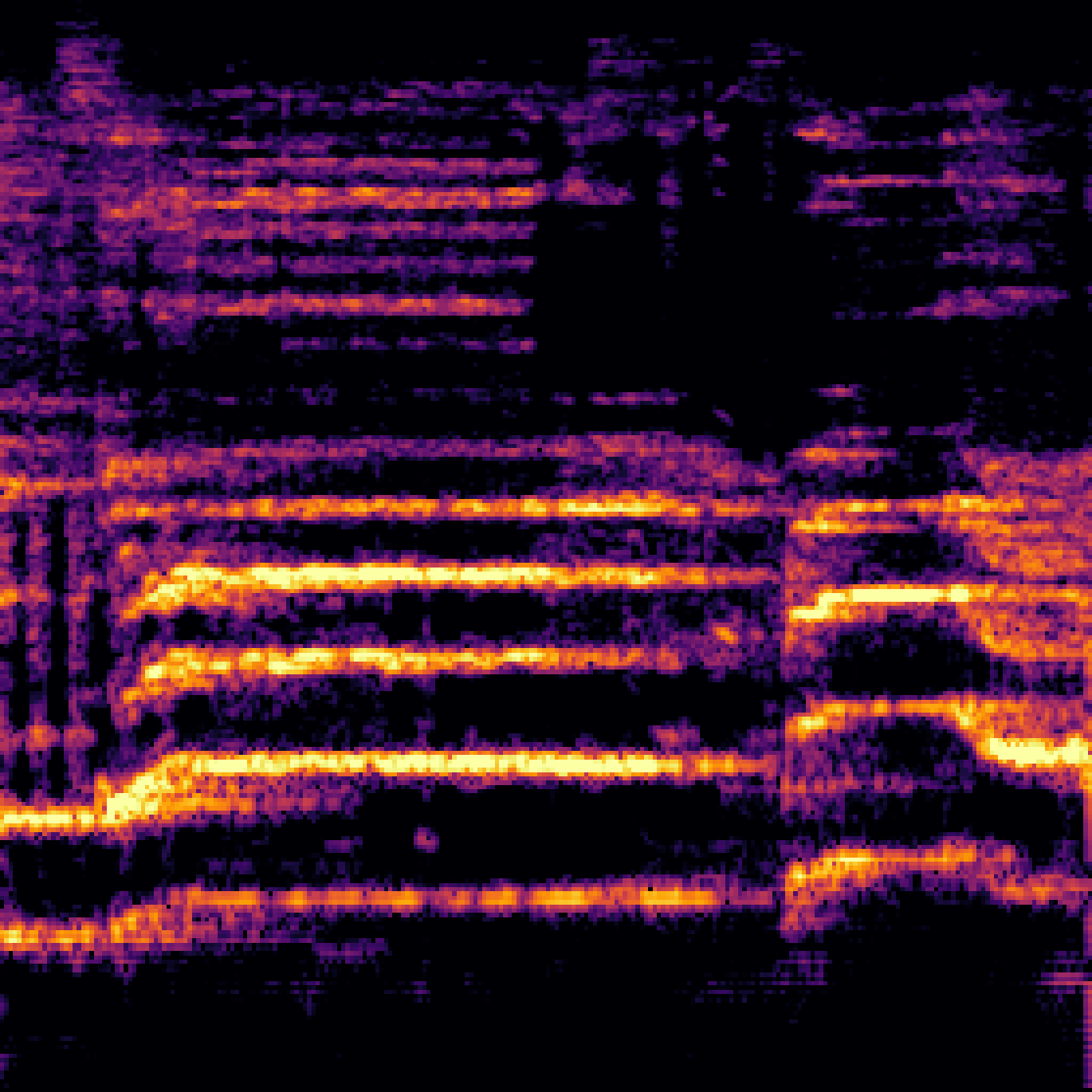
|
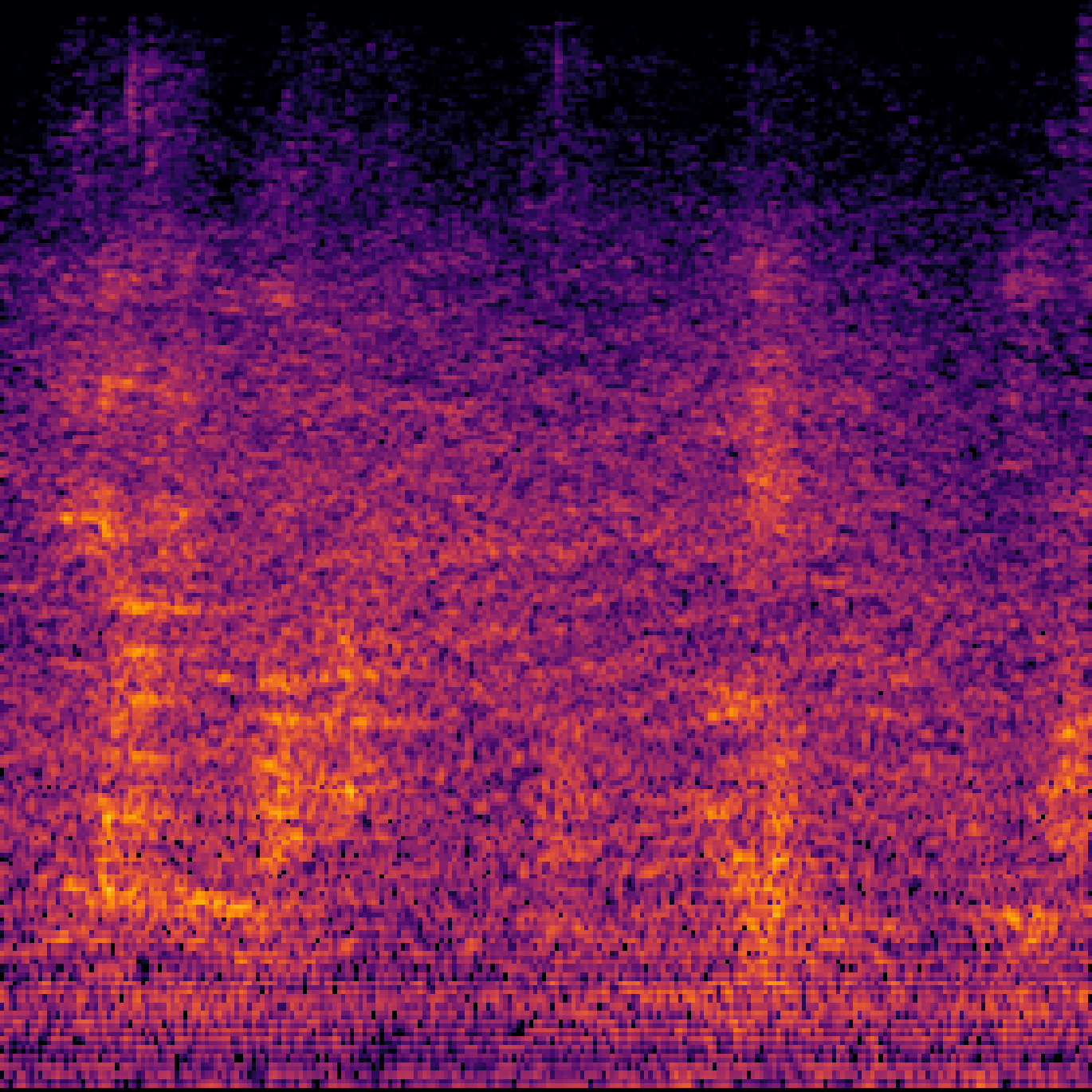
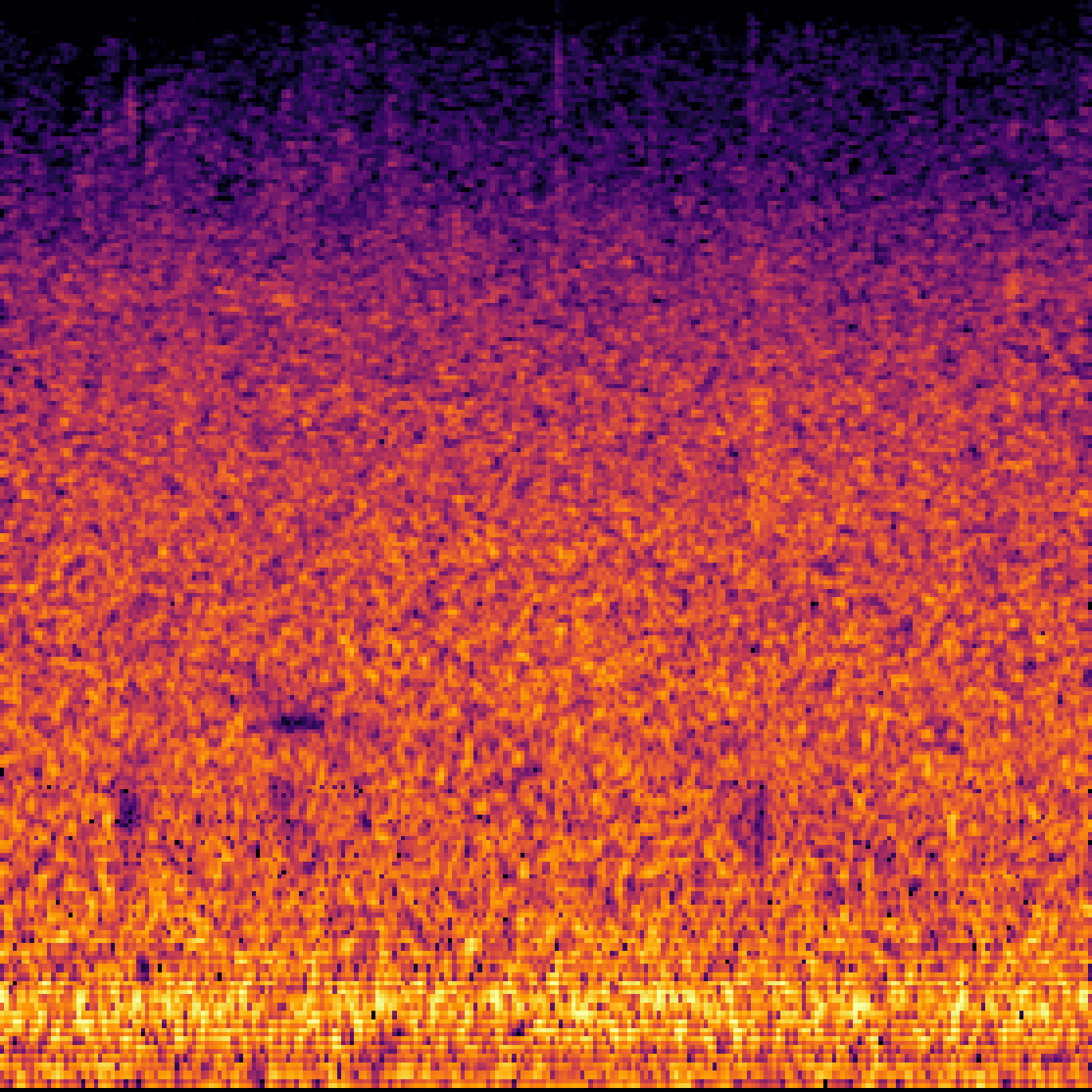
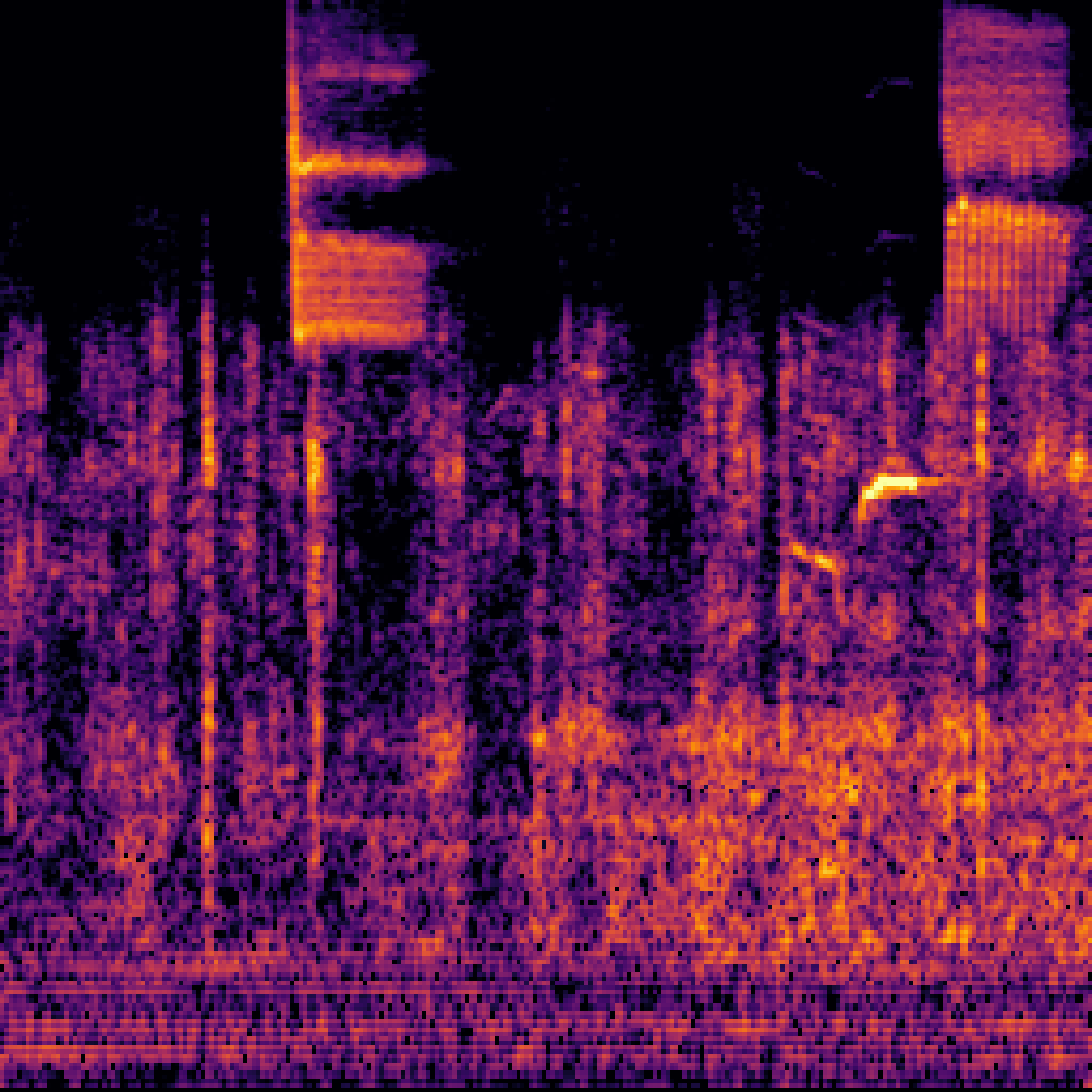
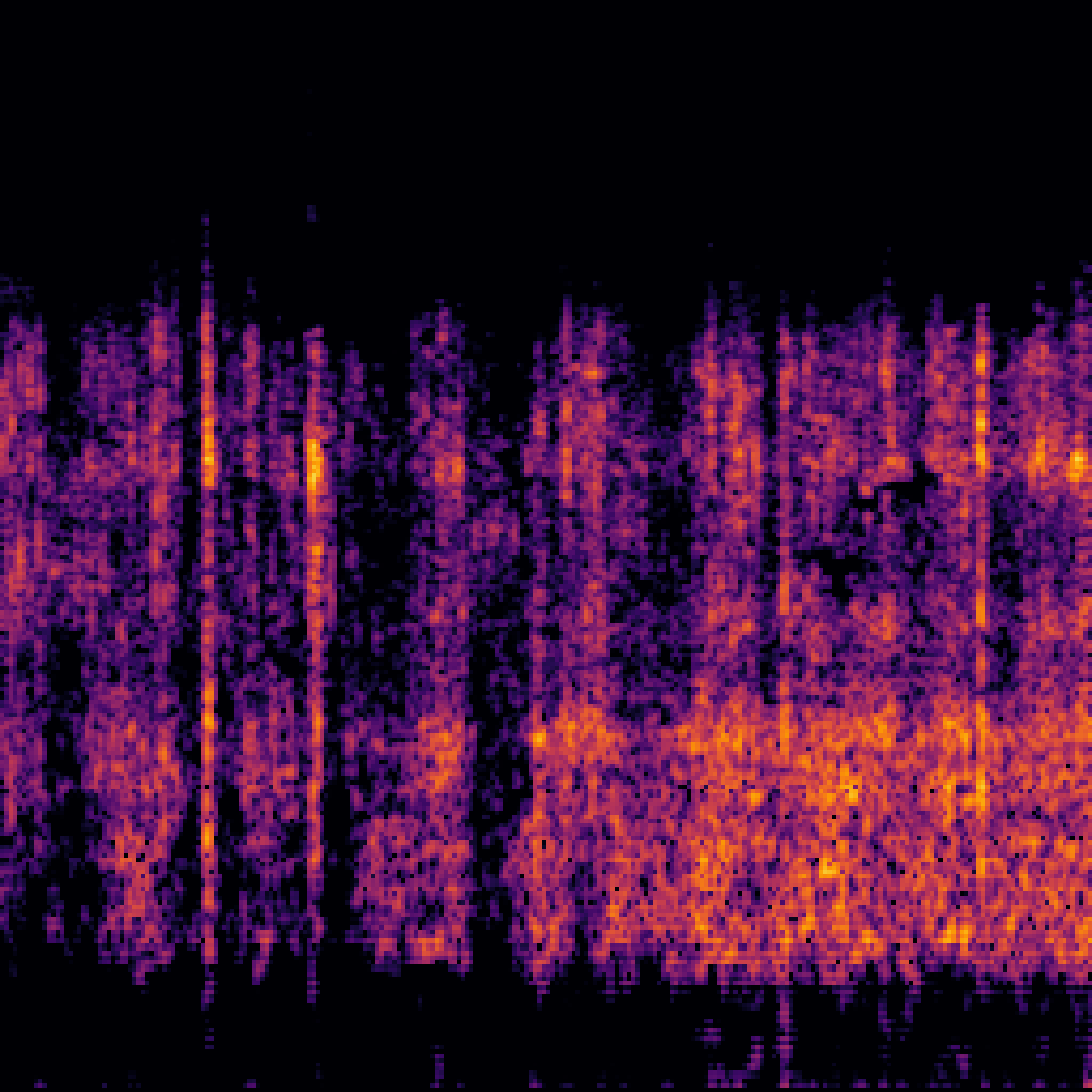
C.Sound Separation with Query-Aug.
| Query | Mixture | Target | OmniSEP | OmniSEP+Query-Aug |
|---|---|---|---|---|

|
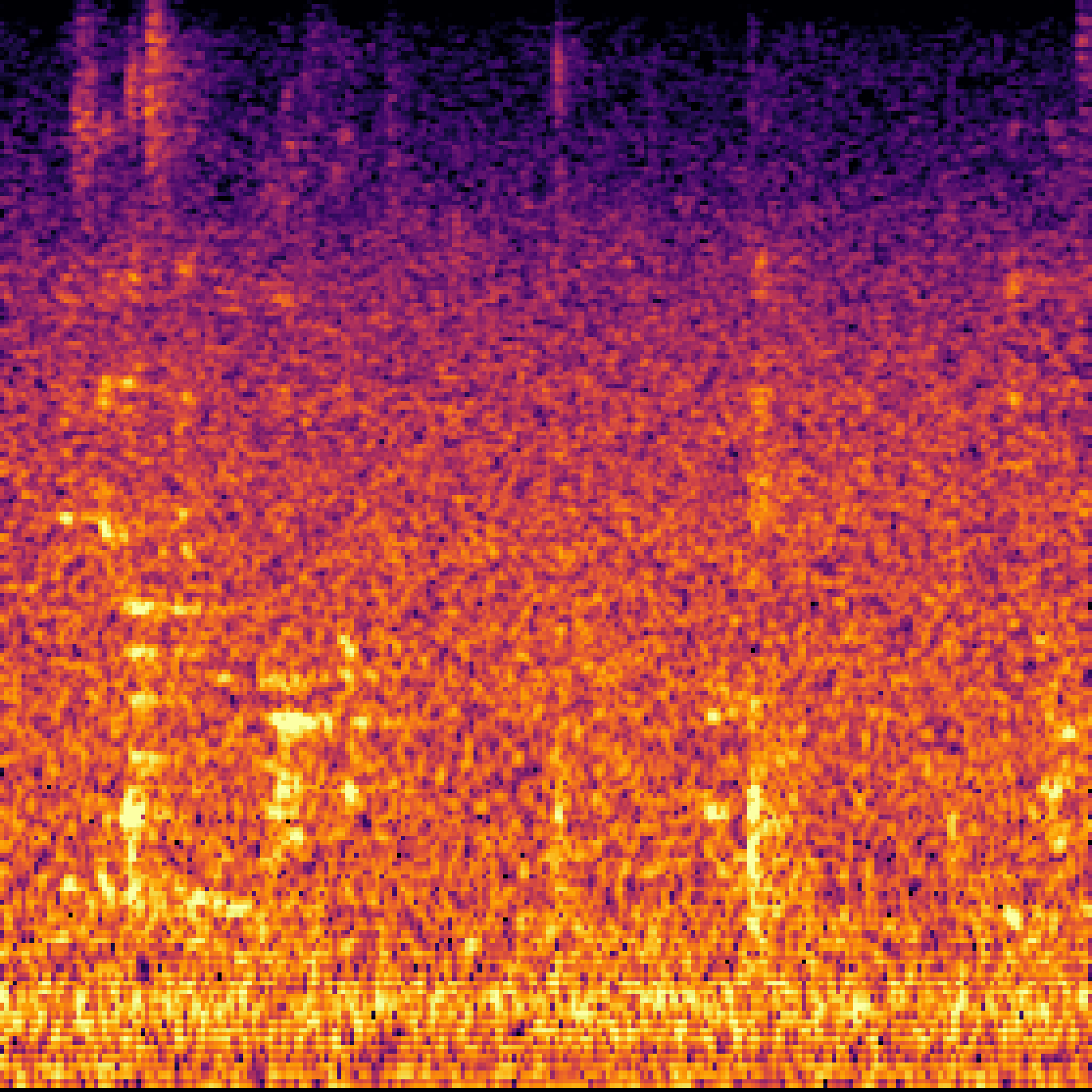
|
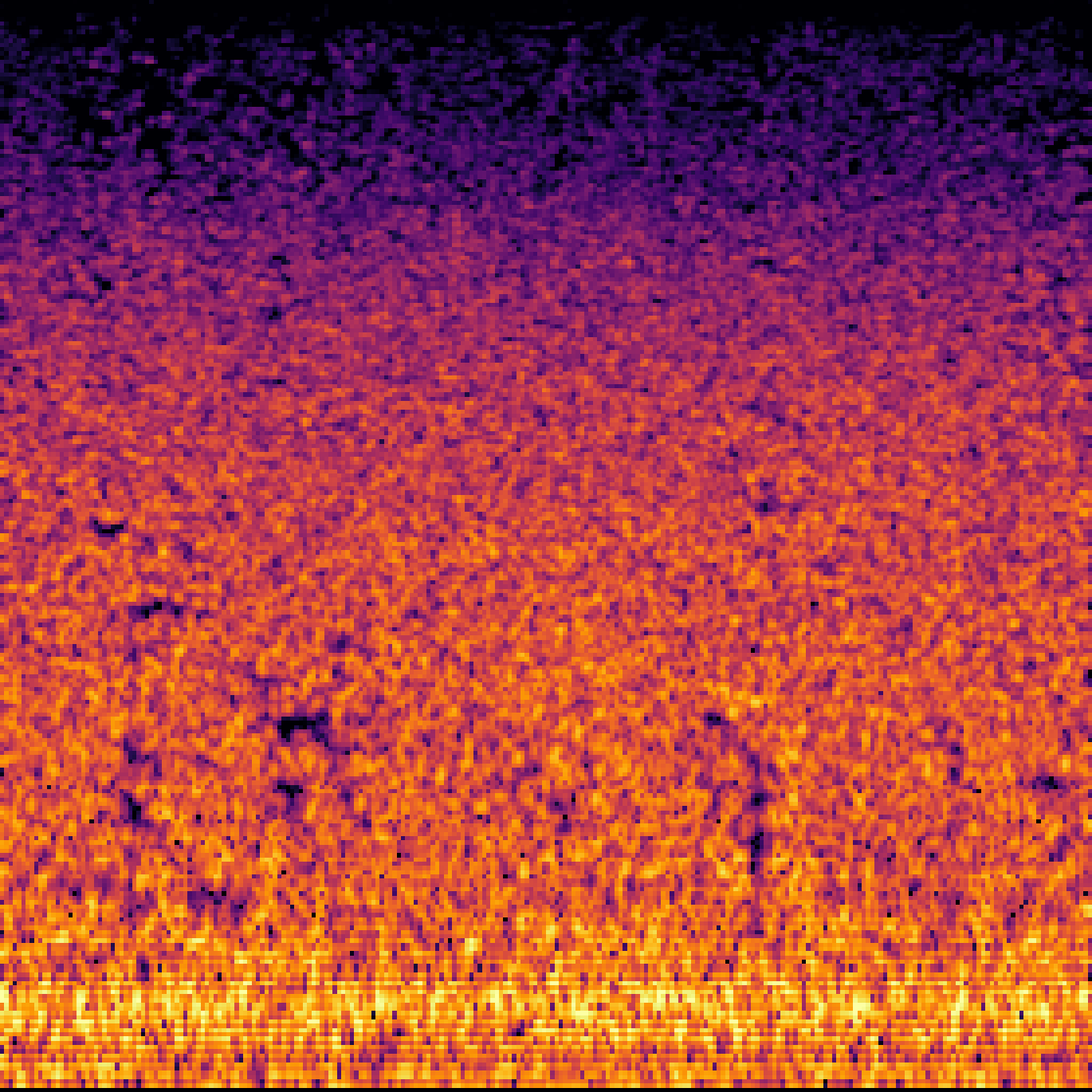
|
|
|

|
|
|
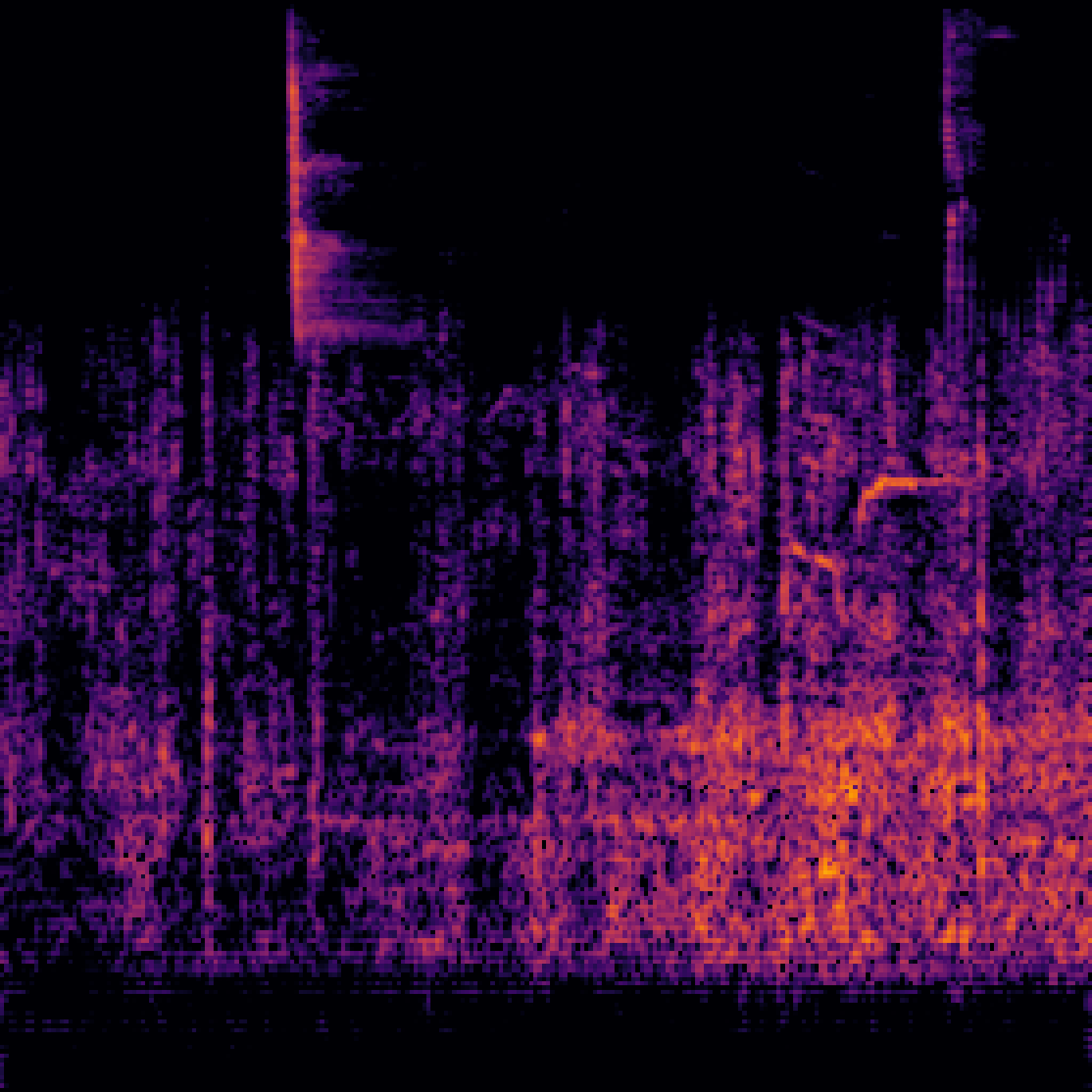
|
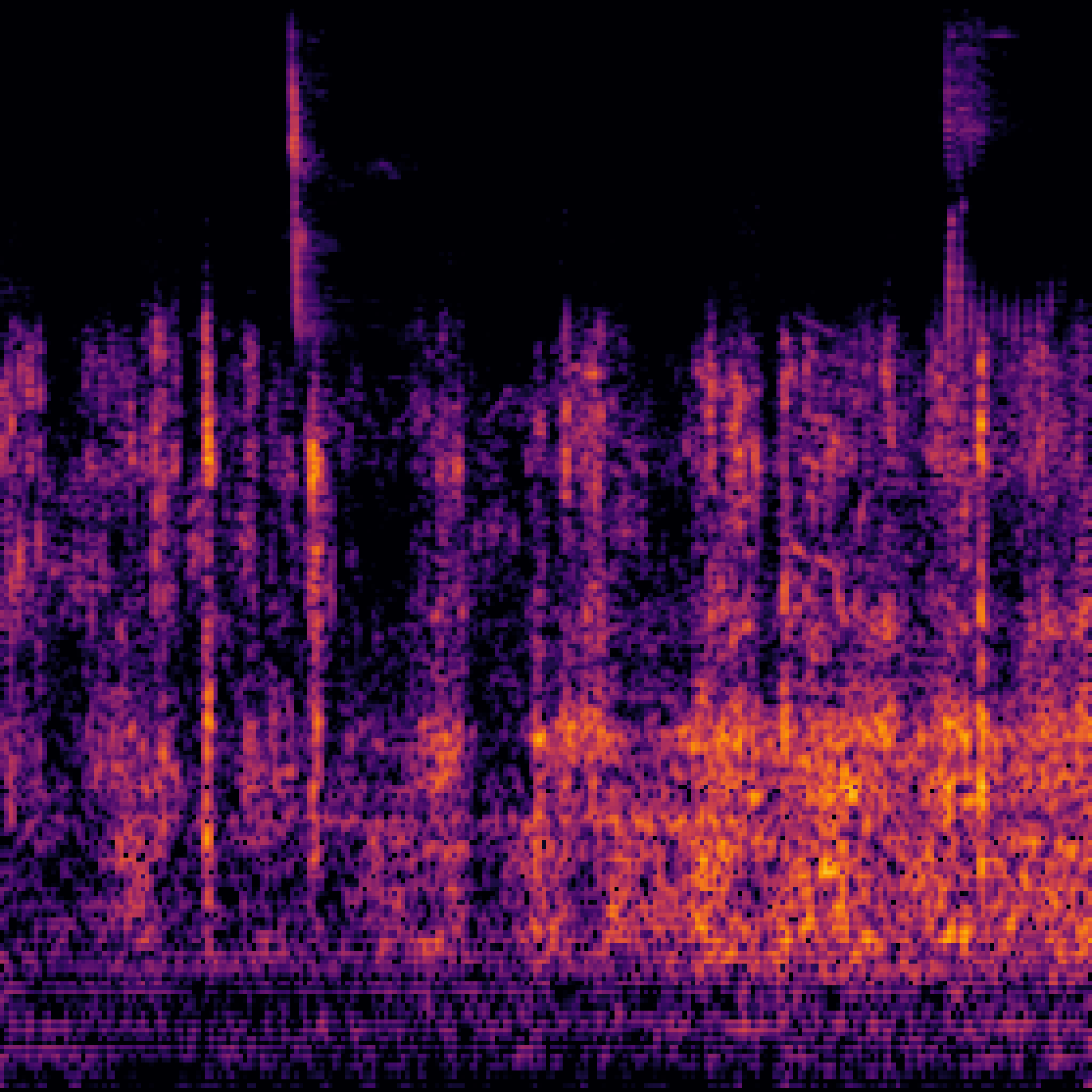
|
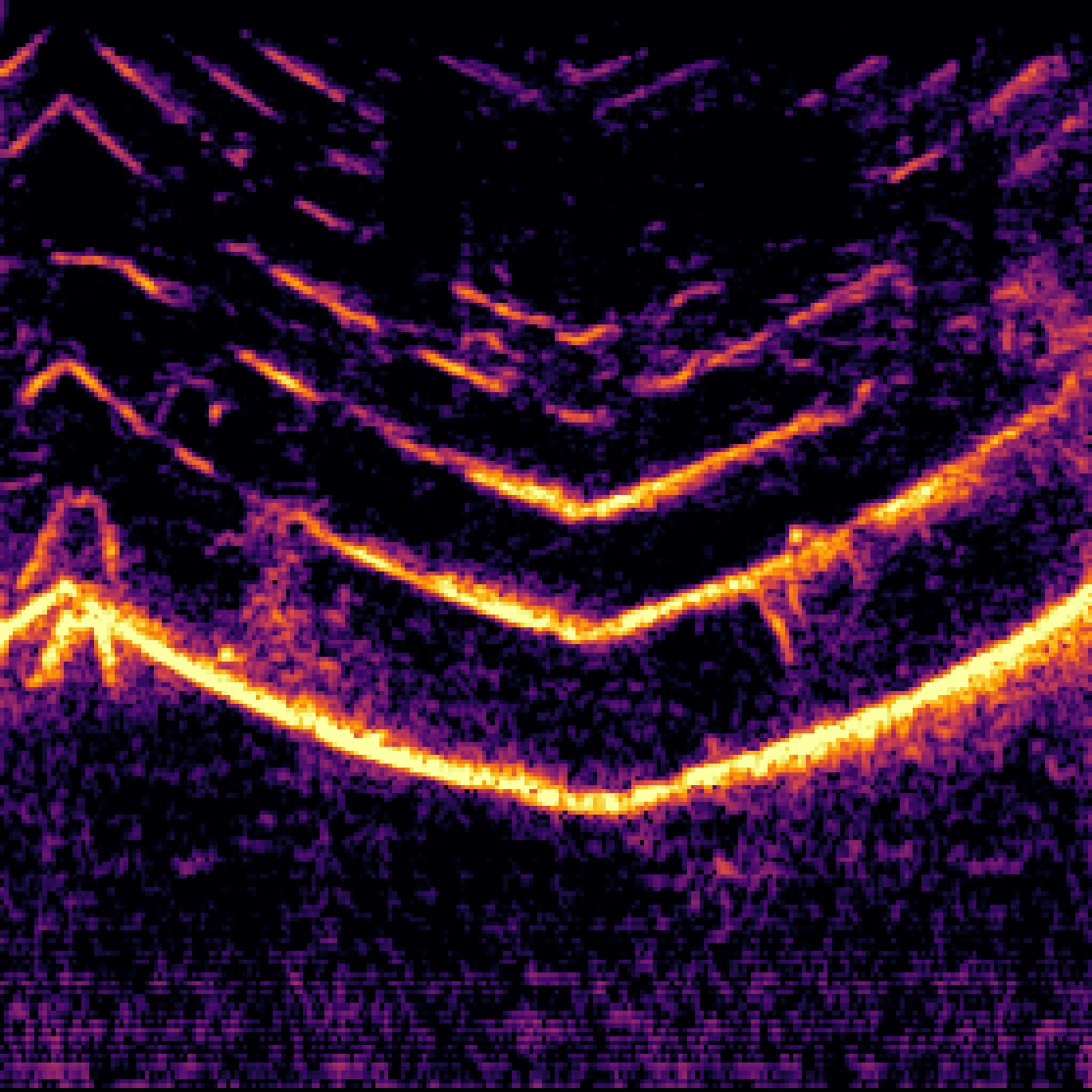
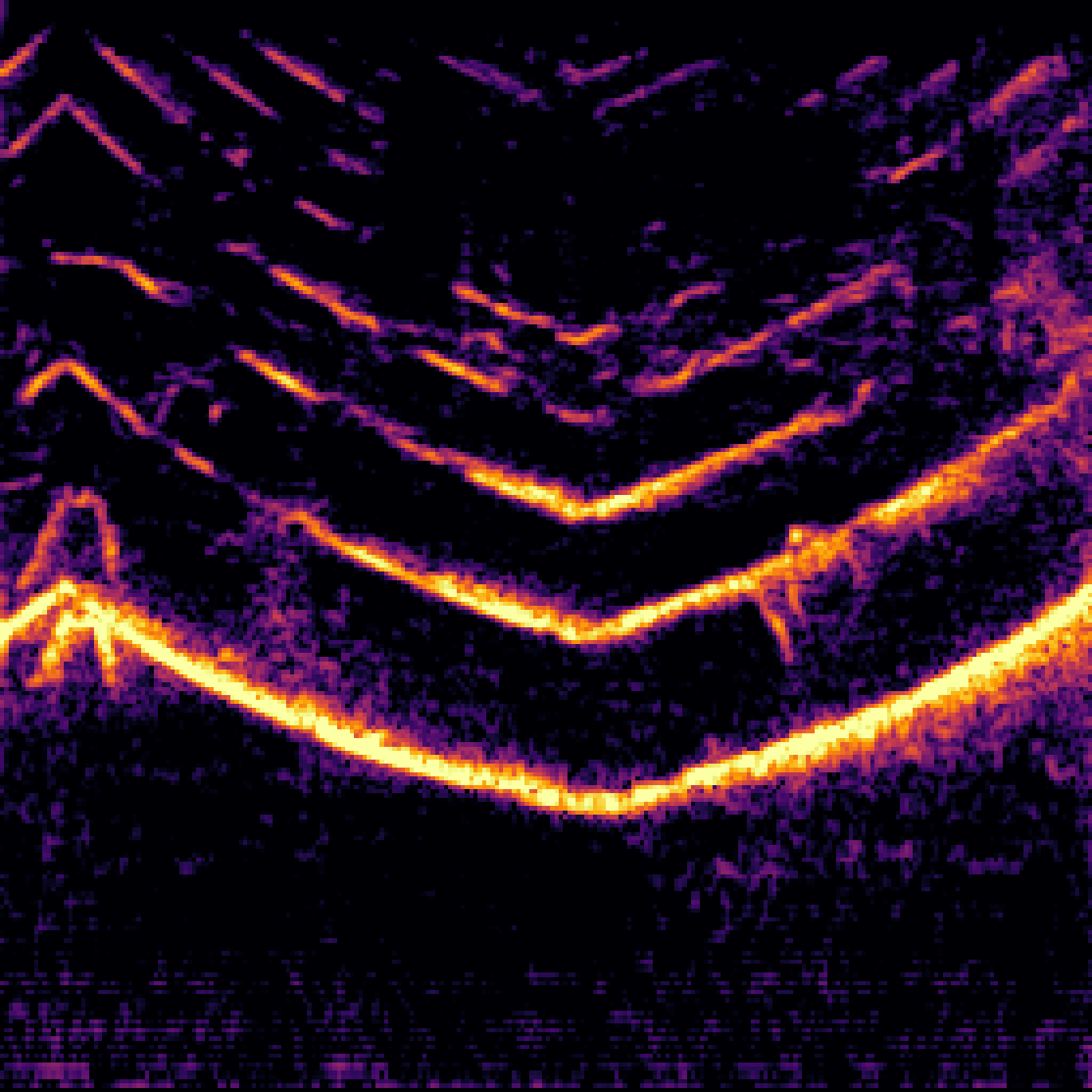
D.AudioSep with Query-Aug.
| Query | Mixture | Target | AudioSep | AudioSep+Query-Aug |
|---|---|---|---|---|
|
|
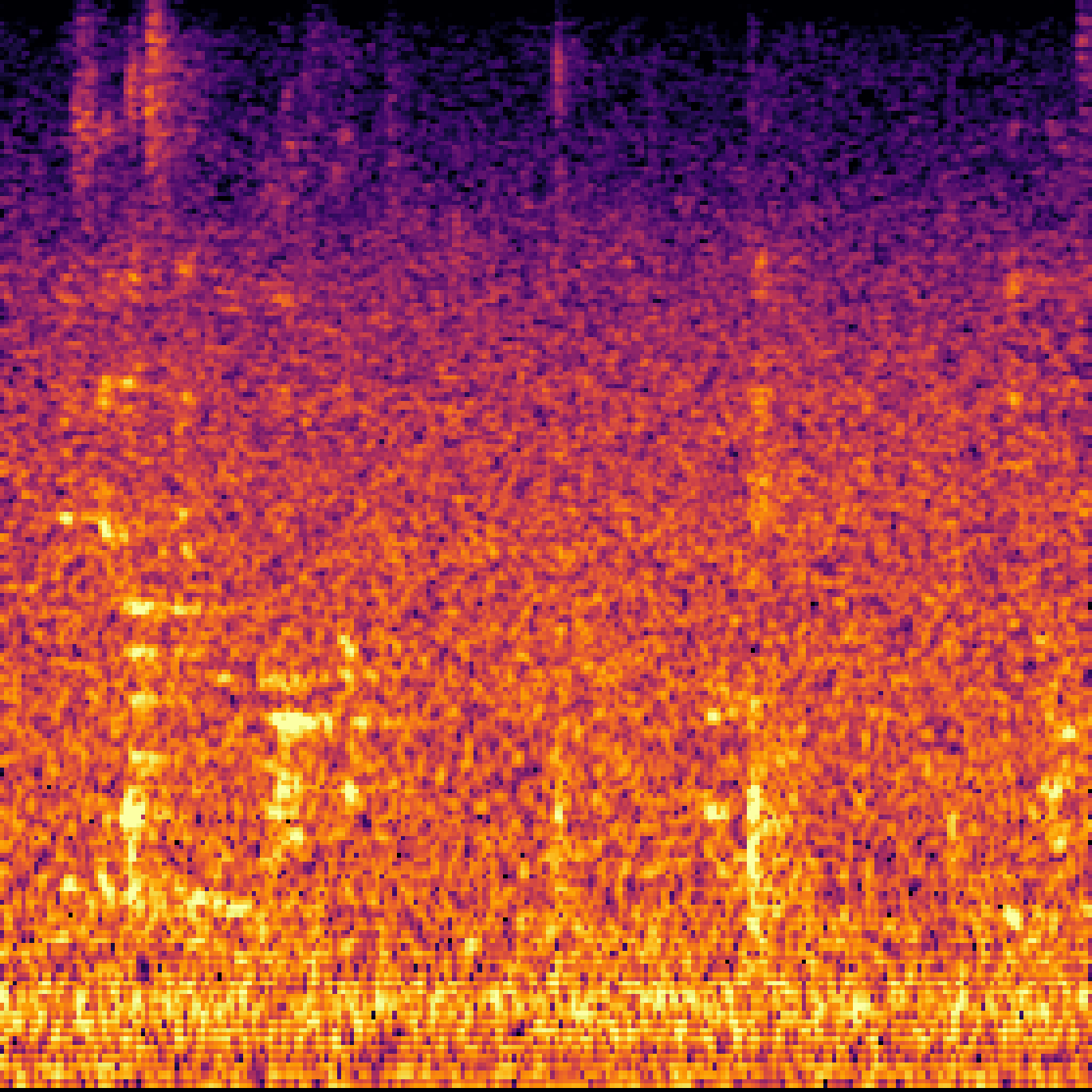
|
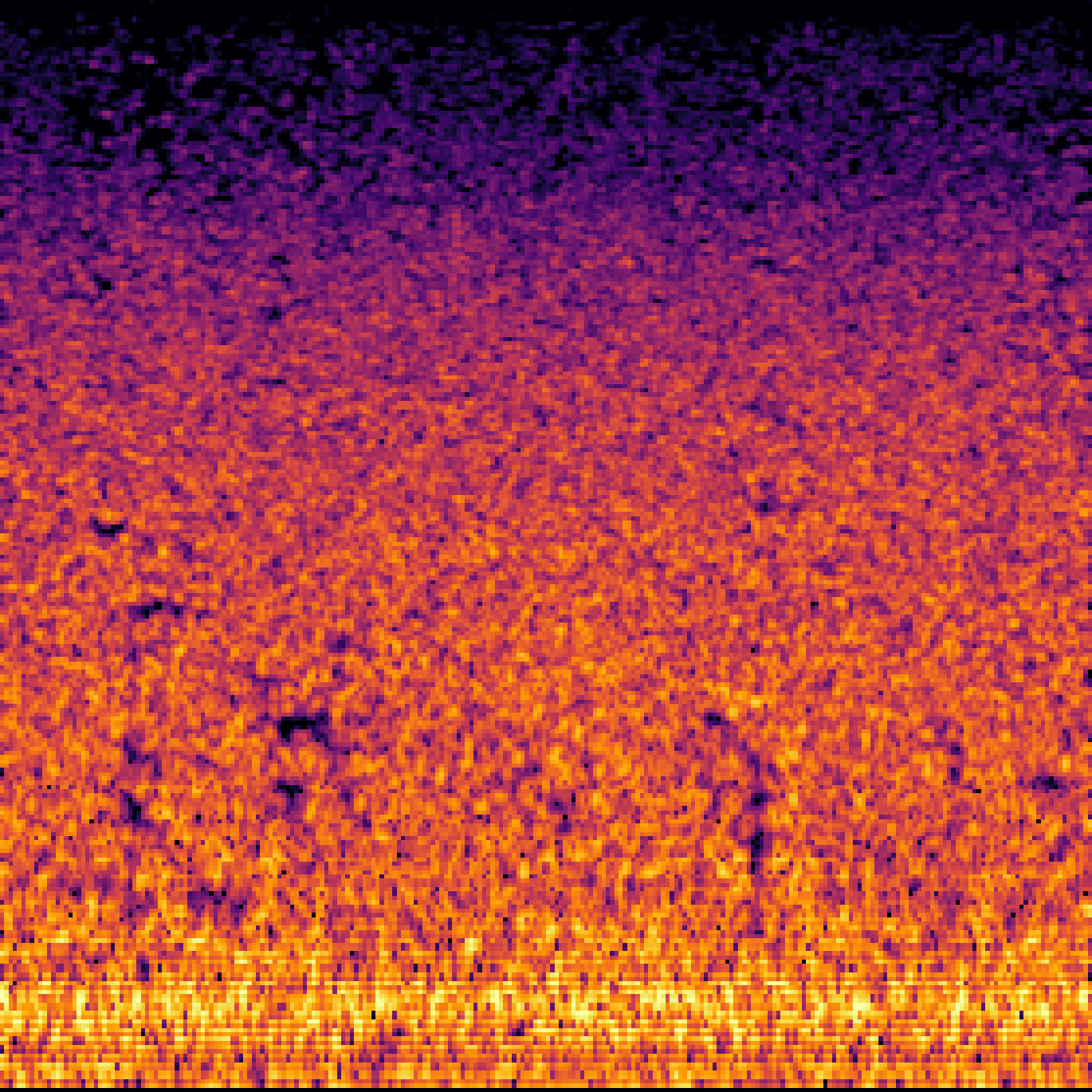
|
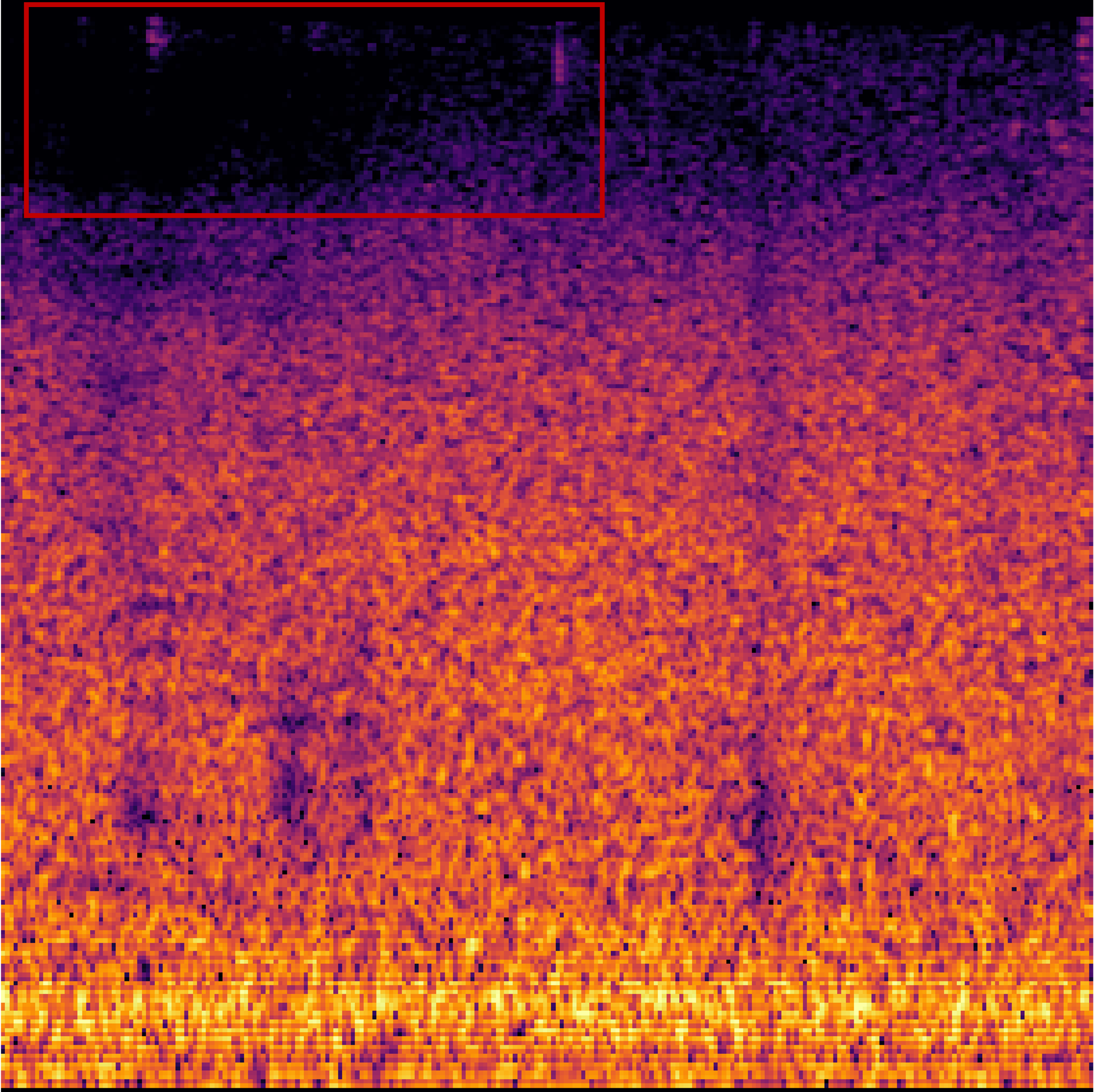
|
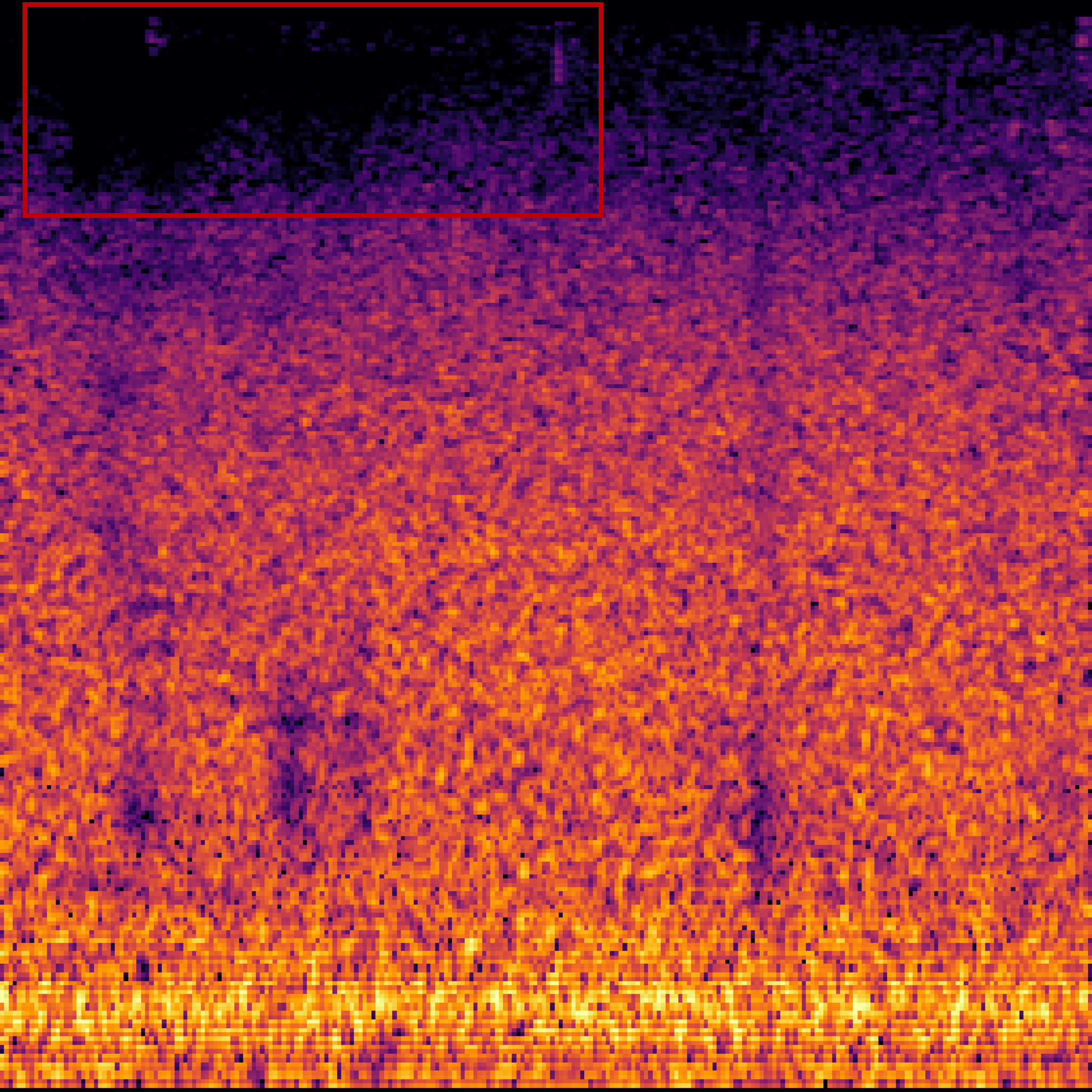
|

|
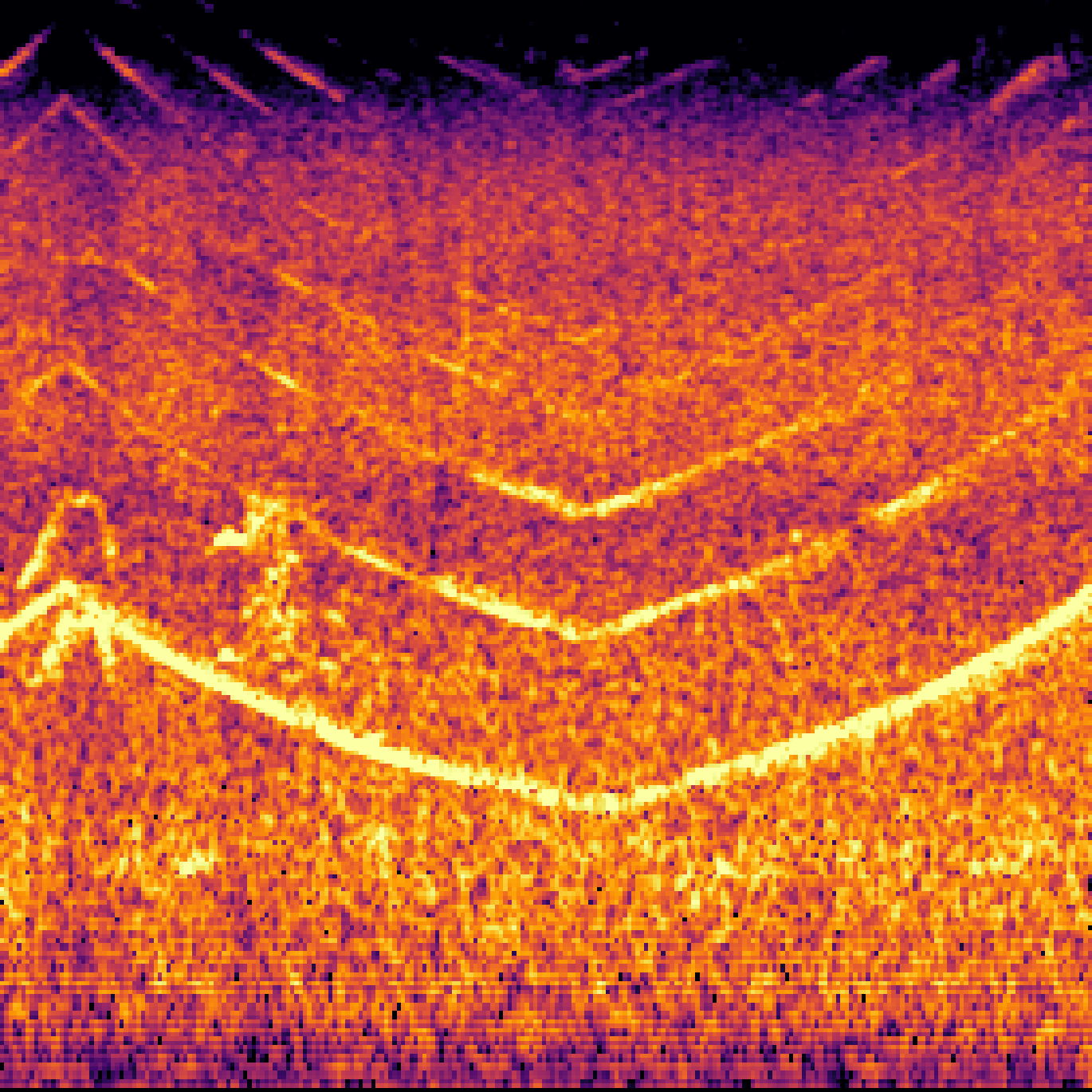
|
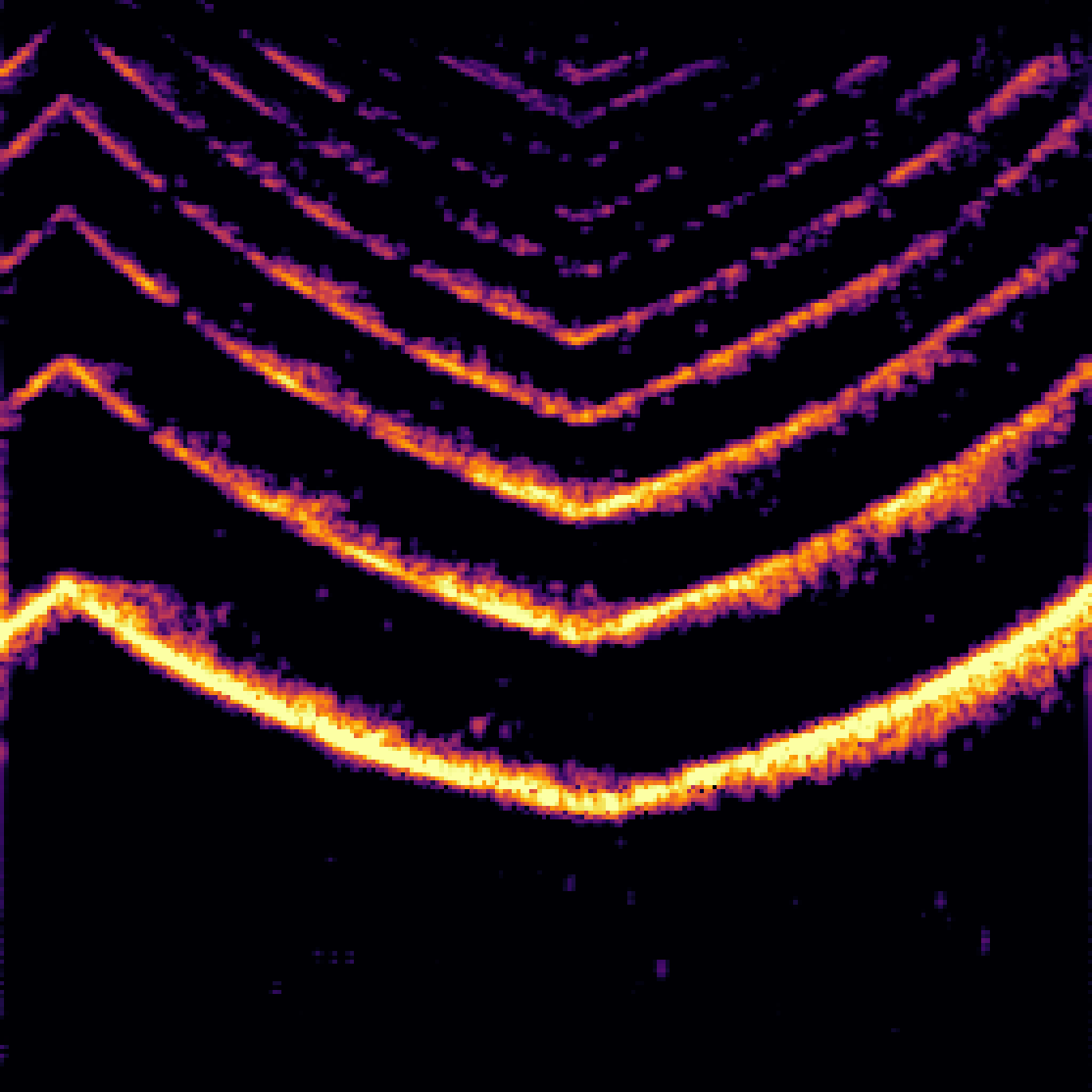
|
|
|
E.Sound Separation on Real Videos.
{kind=link}
| original video | Text | Text - Text (negative) | |
|---|---|---|---|
| Sample2 |
{kind=link}
{kind=link}
| original video | Text | Text - Audio (negative) | |
|---|---|---|---|
| Sample3 |
{kind=link}
F. More Examples on Negative-Query.
| original video | AudioSep( Text ) | OmniSep( Text ) | OmniSep( Text )+ Audio (negative) | |
|---|---|---|---|---|
| Sample1 |
| original video | CLIPSEP( Image ) | OmniSep( Image ) | OmniSep( Image )+ Audio (negative) | |
|---|---|---|---|---|
| Sample2 |
{kind=link}